self-instruct
指令数据定义:
${I_t} \$ 代表要生成的instructions集合,$t$代表task。
$ {(X_{t,i},Y_{t,j})}^{n_t}_{i=1}$代表每个task $t$包括$n_t$个input-output instances。
$M(I_t,X_{t,i})=Y_{t,i}$代表对于模型$M$给定instruction 和 input ,期望其生成对应的output, $i\in {1,…,n_t}$
数据生成
生成instruction
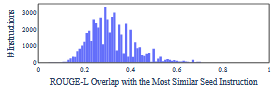
针对self-instruct,我们首先初始化一个任务池包含175个tasks,在生成instruction环节,我们随机抽取8个instruction(6个是原始instruction seed 2个采样自新生成的instruction),按照下面的prompt格式来生成
instance 生成
给定指令和他们的任务类型,然后独立的为这些instruction生成instances。
第一种方法是输入优先的方法,首先根据指令提出输入字段,然后生成相应的输出。
input-first

对偏向于一个标签的输入进行评分,特别是对于分类任务(例如,对于语法错误检测,它通常生成语法输入)。因此,self-instruct还提出了一种用于分类任务的输出优先方法,其中self-instruct首先生成可能的类标签,然后根据每个类标签调节输入生成。
output-first

数据过滤
为了鼓励多样性,只有当新指令与任何现有指令的 ROUGE-L 相似度小于 0.7 时,才会将新指令添加到任务池中。
模型微调
将指令和实例输入连接起来作为提示,并训练模型以标准监督方式生成实例输出。为了使模型对不同格式具有鲁棒性,我们使用多个模板将指令和实例输入一起编码。例如,指令可以加或不加“Task:”前缀,输入可以加或不加“Input:”前缀,提示末尾可以加或不加“Output:”,中间可以放不同数量的换行符等。
分析
多样性
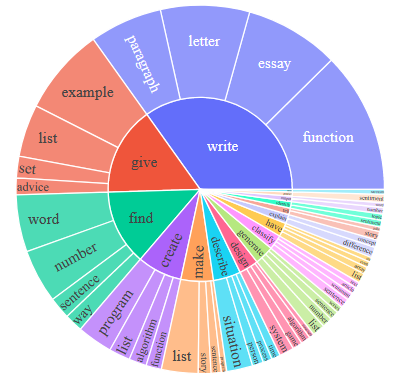
这段话的意思是,研究人员使用了一个名为 Berkeley Neural Parser (伯克利神经句法分析器) 的工具,来分析他们数据集中 52,445 条指令的语法结构。 他们这样做的目的是为了从每条指令中提取一个核心的“动词 + 名词”组合。 具体提取过程如下:
- $\textbf{句法分析 (Parse):}$ 用分析器处理每条指令,得到一个语法树。
- $\textbf{提取动词:} $找到离语法树“根节点”最近的那个动词 (这通常是句子的主要动词)。
- $\textbf{提取宾语:}$ 找到这个动词的第一个直接名词宾语 (即动作的直接承受者)。
最终结果是: 在 52,445 条指令中,有 26,559 条 (大约一半) 包含了这种清晰的“(主)动词 + (其)直接名词宾语”结构。举个例子:
- $\textbf{指令:}$ “Create a brief summary of the solar system.’’
- $\textbf{分析:} $
- $\textbf{根动词:} $”Create’’ (创建)
- $\textbf{直接名词宾语:} $”summary’’ (摘要)
- $\textbf{结果:} $这条指令$\textbf{包含}$该结构。
- $\textbf{指令:}$”Is the sky blue?’’
- $\textbf{分析:}$
- $\textbf{根动词:}$ “Is’’ (是)
- $\textbf{直接名词宾语:} $(无)
- $\textbf{结果:}$ 这条指令$\textbf{不包含}$该结构。
同时测试了生成的内容和175个种子instruction的ROUGE-L分数