Recommender Systems with Generative Retrieval
Introduction
现代推荐系统采用retrieve-and-rank机制。在检索阶段先选出一组候选者,然后在rank阶段对其进行排名,因为rank阶段只能看到候选者,因此检索阶段的候选者必须要保证高度相关。
检索模型:
- 利用矩阵分解来在相同空间学习query和candidate的embeddings。
- dual-encoder 架构(一个用于query另一个用于candidate),使用inner-product将query和candidate embeddings嵌入在同一空间中。在推理阶段,将所有candidate的embeddings提前计算出来,
- Maximum Inner Product Search (MIPS) space:旨在最大化查询与带检索数据项之间的内积。可以用下面的公式表示出来:$argmax_{i \in S}<x_i,q>$,在一组labes $S$上定义的向量数据库$x_i$
Method
Semantic ID generation using content features
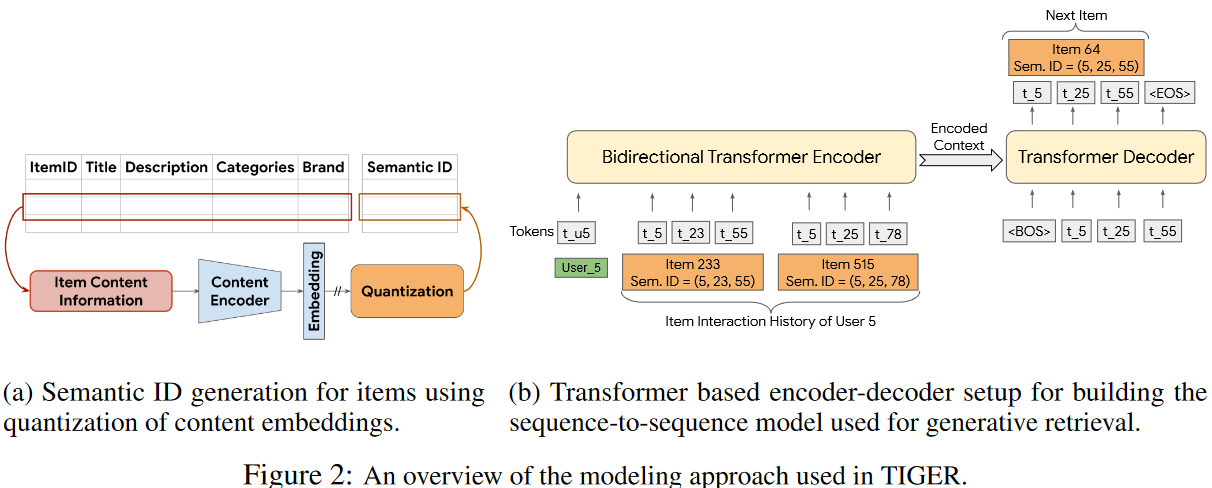
这一阶段涉及将item content features编码成embeddings然后将embedding量化到语义codeword元组中。
- Semantic ID Generation
我们假设每一个item都和捕获了有用的语义信息的content features相关联(图片,title等),然后使用通用的文本编码器: BERT、Sentence-T5来将item的文本features编码为embedding。将语义ID定义为长度为m的codewords元组。元组中的每一个codeword来自不同的codebook。因此其能唯一表示的item数量等于codebook size的乘积。同时相似的item希望能有相近的语义ID,例如 (10,21,35)和(10,23,32)更相似。
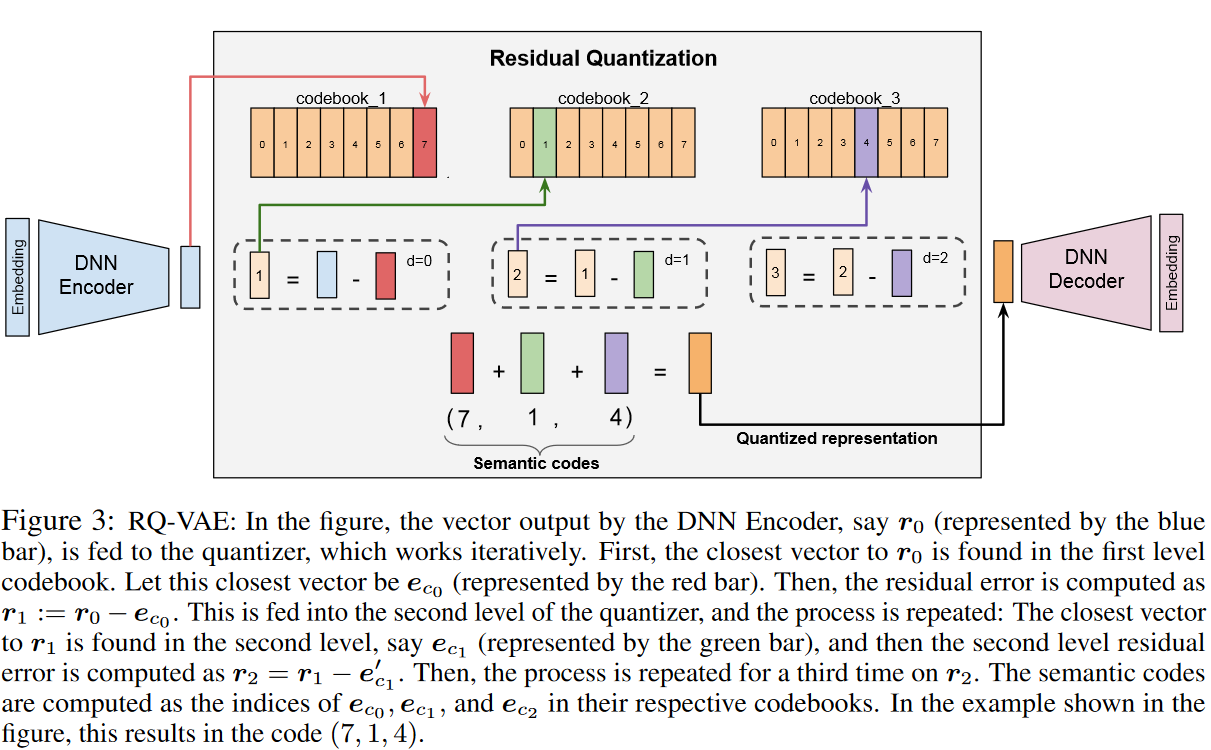
量化过程采用Residual-Quantized Variational AutoEncoder (RQ-VAE),其计算方式见上图,DNN编码器的向量输出,例如R0(由蓝色棒代表),被馈送到量化器中,首先,在第一级代码簿中找到了最接近R0的向量。让此最接近的向量为EC0(由红色棒表示)。然后,将残差误差计算为R1:= R0 - EC0。将其馈入量化器的第二级,然后重复该过程:在第二级中发现了最接近R1的向量,例如EC1(由绿色条表示),然后将第二级残差误差计算为R2 = R1 -E’C1。然后,在R2上第三次重复该过程。语义代码在其各自的代码簿中计算为EC0,EC1和EC2的索引。在图中所示的示例中,这将在代码(7、1、4)中产生。
Training a generative recommender system on Semantic IDs
在获得Semantic ID$(c_0,…,c_{m-1})$后,表征$z$被量化为$\hat{z}=\sum_{d=0}^{m-1}e_{c_i}$这里的e就是codebook中的向量,然后将$\hat z$输入的decoder里尝试重建输入$x$。因此训练loss为如下形式:
$$
L(x)=L_{recon}+L_{rqvac}\
L_{recon} = ||x-\hat{x}||^2\
L_{rqvac} = \sum_{d=0}^{m-1}||sg[r_i]-e_{c_i}||^2+\beta||r_i-sg[e_{c_i}]||^2
$$
sg代表stop-gradient operation。这个loss联合训练encoder,decoder以及codebook。
同时为了防止输入被映射到少量的codebook向量中的codebook collapse,在第一个训练batch中应用k-means算法,并使用质心作为初始化。
Generative Retrieval with Semantic IDs
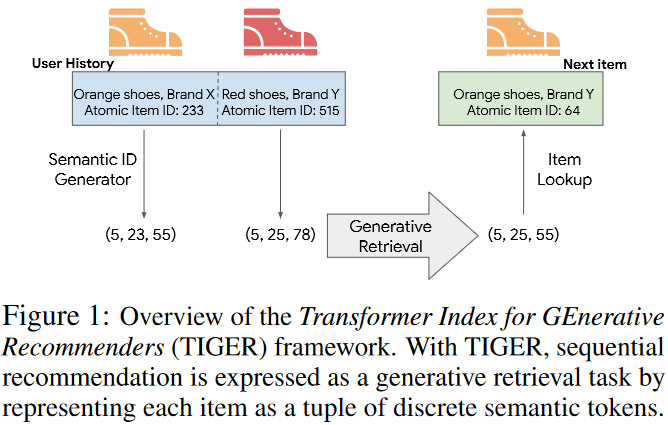
将用户的交互序列定义为:$(item_1,item_2,…,item_n)$,推荐的目标就是预测出下一个item $item_{n+1}$对于$item_i$其会有如下的semantic id $(c_{i,0},…,c_{i,m-1})$那么其交互序列可表示为: $(c_{1,0},…,c_{1,m-1},c_{2,0},…,c_{2,m-1},c_{n,0},…,c_{n,m-1})$
将其输入并直接生成$(c_{n+1,0},…,c_{n+1,m-1})$