Multimodal Pre-training for Sequential Recommendation via Contrastive Learning
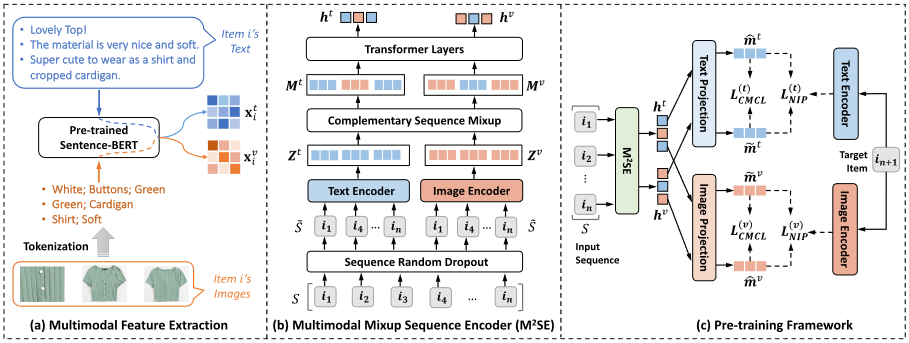
Method
Task Setting
$I$代表item的集合,$S={i_1,…,i_n}$代表用户行为序列,n项是根据交互的timestamp排序的结果。对于每一个item $i$其包含一个集合的图片$V_i={v_1^i,…,v^i_{|V_i|}}$以及文字说明$T_i={t_1^i,…,t_{|T_i|}^i}$。
Multimodal Feature Extraction
Text Feature Extraction
对于$T_i$中的每一个文本,使用BERT获取其的隐藏表征。起始的文本特征$x_i^t$是所有文本特征的堆叠。
$$
x_i^t=stack[BERT(t_1^i),…,BERT(t_{T_i}^i)]
$$
$x_t^i\in R^{|T_i| \times d}$
Image Feature Extraction
$$
f(w) = \text{sim} \left( \text{CLIP} \left( v^i_{\ell} \right), \text{CLIP}(w) \right) \quad \forall w \in \mathcal{D},\
v^i_{\ell} = \text{BERT} \left( \text{concat} \left( \text{TopN} \left( { f(w_1), \ldots, f(w_{|\mathcal{D}|}) }, N \right) \right) \right), \
\mathbf{x}^v_i = \text{stack} \left[ v^i_1, v^i_2, \ldots, v^i_{|\mathcal{V}_i|} \right],
$$
直接使用image encoder提取的特征可能包含许多不重要的信息,因此直接使用CLIP通过计算相似度,直接补充TAG信息,将这些TAG文本作为句子,用BERT模型提取特征并拼接形成图像特征。
$ \mathbf{x}^v_i \in R^{|V_i| \times d }$,w是word dictionary D中的text token。
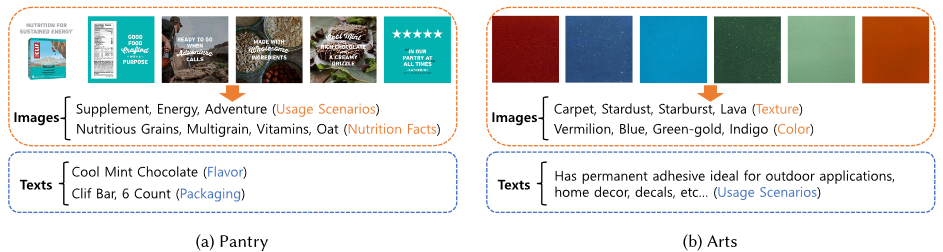
上图展示了使用CLIP补充数据集描述中欠缺的文本信息的示例。
Multimodal Mixup Sequence Encoder
为了编码从item中提取的多模式特征编码用户序列,文章提出全新的骨干网络,$M^2SE$。其包含4个关键组件:
- sequence random dropout
- text and image encoders
- complementary sequence mixup
- transformer layers
Sequence Random Dropout
该模块按照drop ratio参数随机消除掉序列中的一部分items。
Text and Image Encoders
- 文本编码器
在文本编码器中,每个项目 $$i \in \hat{S}$$ 由其初始文本特征 $$x^t_i$$ 表示。注意力层由两个线性变换组成,用于融合 $$i$$ 的句子级嵌入,计算如下:
$$
\alpha^t = \text{softmax} \left( (x^t_i W^t_1 + b^t_1) W^t_2 + b^t_2 \right),
$$
$$
e^t_i = \sum_{j=1}^{|T_i|} \alpha^t_j x^t_i[j, :],
$$
其中 $$W^t_1 \in \mathbb{R}^{d \times d_a}$$,$$W^t_2 \in \mathbb{R}^{d_a}$$,$$b^t_1 \in \mathbb{R}^{d_a}$$,和 $$b^t_2 \in \mathbb{R}$$ 是可学习的参数。$$d_a$$ 是注意力维度大小。$$\alpha^t_j$$ 是 $$\alpha^t$$ 的第j个元素,$$x^t_i[j, :]$$ 表示特征矩阵 $$x^t_i$$ 的第j行。$e^t_i\in R^{d}$其相当于自注意力后的特征。
然后,使用MoE来增加模型适应融合模态表示 $$e^t_i$$ 的能力。每个专家网络由一个线性变换、一个dropout层和一个归一化层组成。令 $$E_k(e^t_i) \in \mathbb{R}^{d_0}$$ 表示第k个专家网络的输出,$$g^t \in \mathbb{R}^O$$ 表示门控网络的输出,计算如下:
$$
E_k(e^t_i) = \text{LayerNorm} \left( \text{Dropout} \left( e^t_i W^t_k \right) \right),
$$
$$
g^t = \text{softmax} \left( e^t_i W^t_3 \right),
$$
其中 $$W^t_3 \in \mathbb{R}^{d \times O}$$ 和 $$W^t_k \in \mathbb{R}^{d \times d_0}$$ 是可学习的参数,O是专家的数量,$$d_0$$ 是隐藏嵌入的维度。然后,MoE网络对项目i的输出如下:
$$
z^t_i = \sum_{k=1}^O g^t_k E_k(e^t_i),
$$
其中 $$z^t_i \in \mathbb{R}^{d_0}$$,$$g^t_k$$ 是来自第k个门控路由器的权重。这里为了简化,省略了方程中的偏置项。MoE网络对 $$\hat{S}$$ 中所有项目的输出被堆叠形成文本编码器的输出,记为 $$Z^t = \text{stack}[z^t_1, z^t_2, \ldots, z^t_{|\hat{S}|}]$$。
MOE其实就是加权多个模型的输出结果。
- 图像编码器
计算方式与上面的情况一致。
Complement Sequence Mixup
解决两种不同模态序列的表征差异。实现逻辑就是设置一个混合比率$p$在0到0.5之间,根据比率将另一模态在上一阶段提取到的嵌入嵌入到本序列中。
Transformer Layers
就是一个L层的多头注意力,并将第L层输出的最后一行作为两种混合模态表征。
Pre-training Objectives
为了更好地捕获不同模态表示之间的相关性,我们提出了两个优化目标,即模态特定的下一项预测和跨模态对比学习,基于混合模态序列表示对骨干模型进行预训练。预训练阶段的工作流程如图1(c)所示。设 $\mathcal{B} = {(S_j, i_j)}_{j=1}^{|\mathcal{B}|}$ 表示一批预训练数据,其中 $S_j$ 表示用户的行为序列,$i_j$ 是其在 $S_j$ 之后的下一个交互项目。利用 M$^2$SE,我们可以获得 $S_j$ 的两个混合模态序列表示 $h^t_j$ 和 $h^v_j$。由于 $h^t_j$ 和 $h^v_j$ 是通过混合模态获得的,我们首先使用两个线性变换将它们映射到文本特征空间和图像特征空间,以便分别计算预训练损失:
$$
\tilde{m}_j^t = h_j^t W_t + b_t,
\
\tilde{m}_j^v = h_j^v W_v + b_v,
\
\tilde{m}_j^{v’} = h_j^t W_t + b_v,
\
\tilde{m}_j^{t’} = h_j^v W_v + b_t,
$$
其中 $W_t, W_v \in \mathbb{R}^{d_0 \times d_0}$ 和 $b_t, b_v \in \mathbb{R}^{d_0}$ 是可学习的参数。受模型预训练中对比学习成功的启发,我们以对比的方式定义预训练目标函数。
Modality-specific Next Item Prediction.
文本特征空间中的下一项预测损失定义如下:
$$
L_{NIP}^{(t)} = - \sum_{j=1}^{|B|} \log \frac{f(\tilde{m}_j^t, z_j^t) + f(\tilde{m}j^v, z_j^t)}{\sum{j’=1}^{|B|} [f(\tilde{m}j^t, z{j’}^t) + f(\tilde{m}j^v, z{j’}^t)]},
$$
其中$f(s, z) = \exp(\text{sim}(s, z)/\tau)$,$\tau$ 是温度超参数。类似地,我们也可以定义图像特征空间中的下一项预测损失 $L_{NIP}^{v}$。这一项损失的意义就是使得图像和文本表征和下一个item的表征接近。利用对比学习