Introduction
传统推荐系统的问题
- 常规推荐系统是基于特定域内离散ID构建的域面向域的系统。因此,他们缺乏开放域的世界知识来获得更好的建议性能(例如,增强用户兴趣建模和项目内容的理解),并在不同的域和平台上传递能力。
- 常规推荐系统通常旨在以数据驱动的方式优化特定的用户反馈,例如点击和购买,在这种方式中,用户偏好和基本动机通常是根据在线收集的用户行为进行隐式建模的。结果,这些系统可能缺乏建议解释性,并且无法完全理解用户在各种情况下的复杂和波动意图。此外,用户无法通过提供自然语言的详细说明来积极指导推荐系统遵循其要求并自定义建议结果
LLM的应用
本文从工业推荐系统的整个流水线角度来分析。将LLM的应用分为HOW和WHERE来分析。
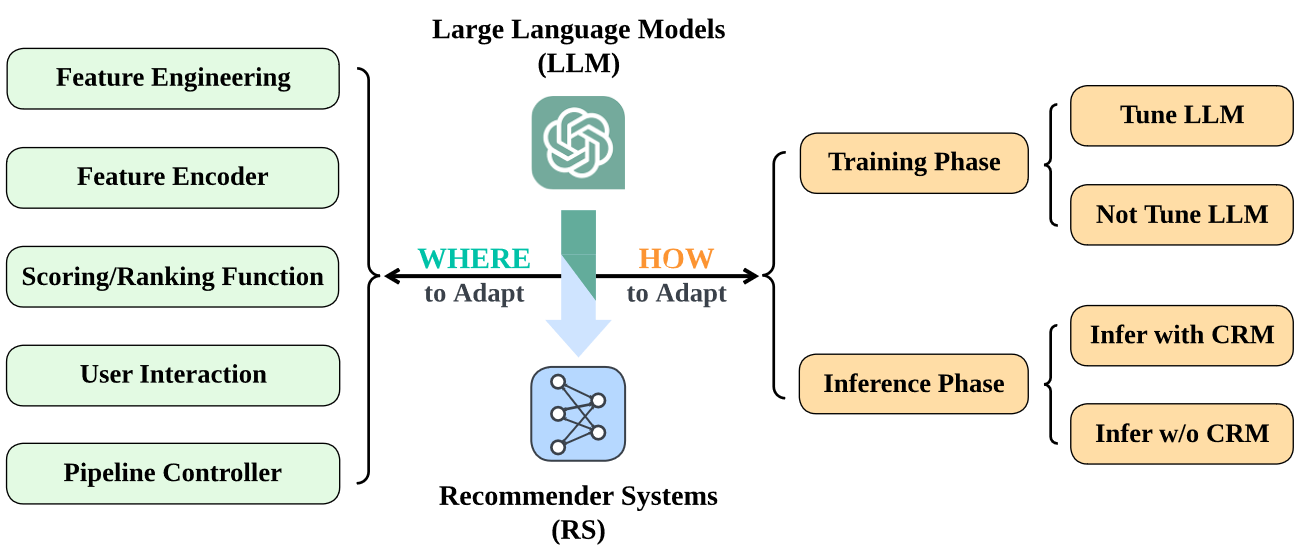
BACKGROUND AND PRELIMINARY
现代推荐系统
推荐系统的核心是为特定用户$u \in U$和特定内容$c$提供items的排名序列$[i_k]^N_{k=1},i_k \in I$,其中$I$和$U$是Item和Users的集合。对于下一个item预测场景对应$N=1$
$$
[i_k]^N_{k=1} \leftarrow RS(u,c,I),u\in U,i_k \in I
$$
现代基于深度学习的推荐系统可以被描述为涵盖六个关键阶段的信息周期:
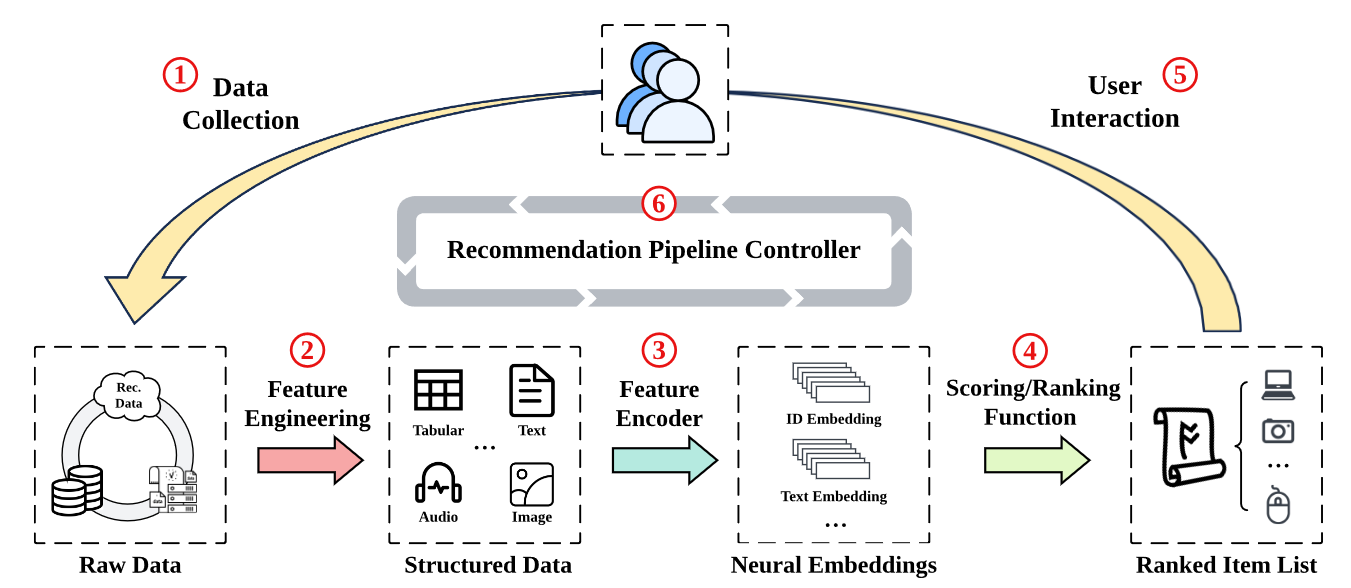
- Data Collection:数据收集阶段通过向用户呈现推荐的项目来收集来自在线服务的明确和隐式反馈。显式反馈表示直接的用户响应,例如评分,而隐式反馈源自用户行为,例如点击,下载和购买。除了收集用户反馈外,要收集的数据还包括一系列原始功能,包括项目属性,用户人口统计信息和上下文信息。
- Feature Engineering:特征工程是选择,操纵,转换和扩大在线收集到的原始数据中的结构化数据的过程,这些数据适合作为神经建议模型的输入。Feature Engineering的输出是各种模态数据通过对应模态编码器编码得到。(可以理解为变成格式化数据)
- Feature Encoder:将在Feature Engineering阶段得到的输出作为输出生成embedding用于下一阶段的评分和排序。
- Scoring/Ranking function:该阶段是推荐系统的核心部分,根据嵌入精准估计用户的偏好和行为。
- User Interaction:用户互动是指我们向目标用户表示推荐的项目的方式,以及用户将反馈还给推荐系统的方式。
- Recommendation Pipeline Control:监视并控制上述整个recommendation pipeline的操作。
也就是对于我们写论文只需要考虑:3和4.最多加一个2
Where to adapt LLM
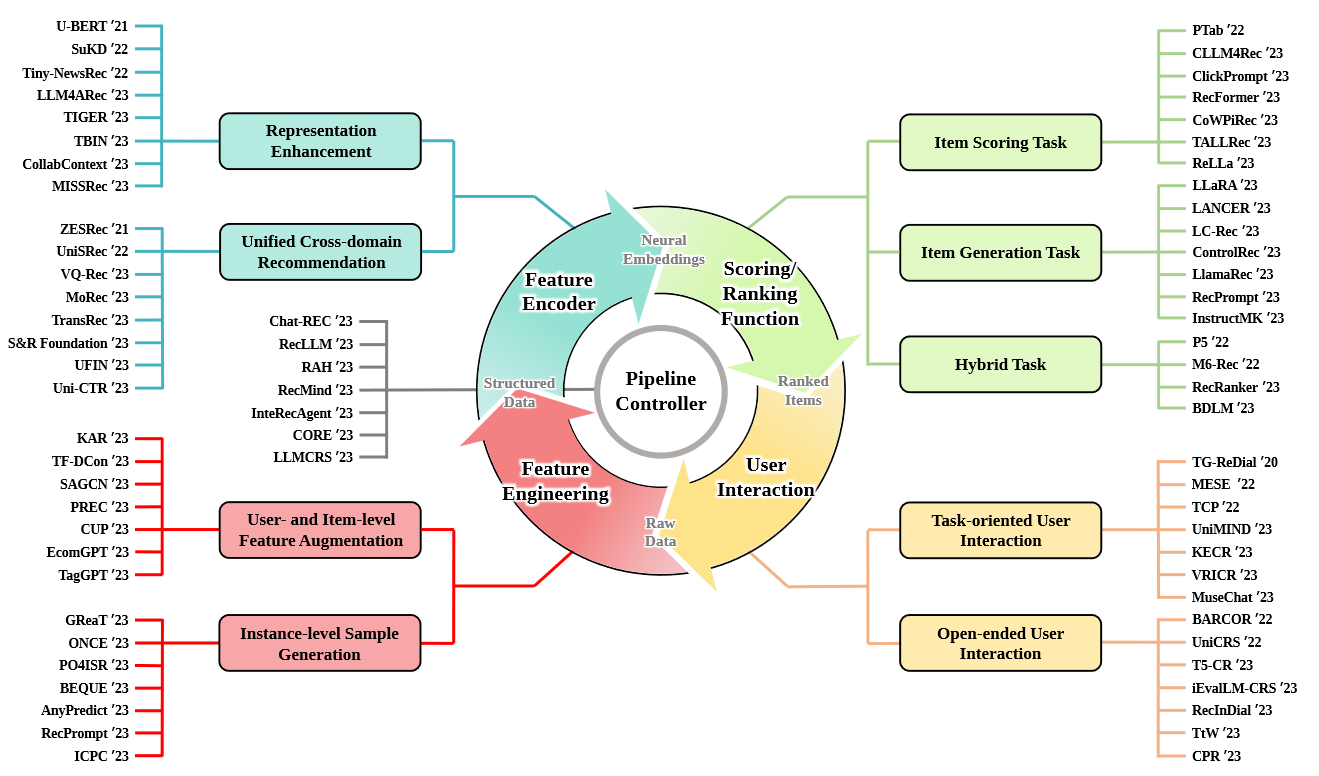
LLM for Feature Engineering
这一阶段将原始feature输入LLM并生成具有各种目标的数据增强的辅助文本功能。例如丰富训练数据,缓解长尾问题。
采用不同的prompt策略来充分利用LLM展示的开放世界知识和推理能力。根据数据的类型,该行的研究工作可以主要分为两类:(1)用户和项目级功能增强,(2)实例级别培训样本生成。
- User- and Item-level Feature Augmentation.:提供更好的用户偏好建模和项目内容的理解。作为代表,KAR [242]采用LLM来生成用户端的首选项知识和项目侧事实知识,这些知识是下游常规推荐模型的插件功能。 SAGCN [124]引入了一种基于链条的提示方法,以发现语义方面感知的交互,该方法在细粒度的语义层面上提供了对用户行为的更清晰的见解。 Cup [201]根据用户评论文本采用CHATGPT,用一些简短的关键字来总结每个用户的兴趣。通过这种方式,用户分析数据在128个令牌之内被凝结,因此可以用小尺度语言模型进一步编码,这些模型受到上下文Windows大小的约束(例如,对于Bert [31])。
- Instance-level Sample Generation.:LLM还被利用来生成合成样品,从而丰富培训数据集并提高模型预测质量。
LLM as Feature Encoder
传统方法一般采用嵌入层获得致密嵌入,LLM可以为后续的推荐模型丰富User/Item表示,利用文本作为桥梁实现跨域推荐。
- Representation Enhancement:Item的内容通常是静态的,用户的兴趣是动态的,需要对用户的行为和基本偏好进行顺序建模。U-BERT将评论文本编码为一系列向量来改善用户表示。LLM4ARec使用GPT2来提取个性化的方面术语和潜在向量。
- Unified Cross-domain Recommendation:在UNISREC [67]中,通过固定的BERT模型学习了跨域顺序推荐的项目表示,然后是轻质MOE增强网络。基于UNISREC,VQ-REC [66]引入了向量量化技术,以更好地使LLM生成的文本嵌入到建议空间。 Uni-CTR [47]利用从共享LLM的层面语义表示来充分捕获不同域之间的共同点,从而导致更好的多域建议。其他作品[52,199]利用固定LLM(例如Chatglm [40],Sheared-llama [243])的统一跨域文本嵌入式嵌入,以使用冷启动的用户/物品或低频率的长尾型特征来解决场景。
LLM as Scoring/Ranking Function
根据LLM解决的不同任务,可以将工作分为3类:
- item scoring task
- item generation task
- hybrid task
Item Scoring Task
$$
C \leftarrow Pre_filter(u,I),\
[i_k]^N_{k=1} \leftarrow Sort({F(u,i)| \forall i \in I})
$$
pre_filter函数用于减少候选item的数量减轻计算量,最终的排名结果可以通过将LLM生成的得分进行排名得到。
$$
h=LLM(x),\
s=LM_Head(h)\in R^V,\
p=softmax(s) \in R^V,\
\hat{t} - p
$$
其中h是final representation,V是vocabulary size,$\hat{t}$是从概率分布p采样的预测token
但是,项目评分任务要求模型对给定的用户项目对(u,i)进行pointwise评分,并且输出应为实数$\hat y = f(u,i)$,而不是生成的离散令牌$\hat t$。输出 应属于一定数值范围内,以指示用户偏好,例如,对于点击率(ctr)估计,$\hat y∈[0,1]$和$\hat y∈[0,5]$进行评级预测。有三种主要的方法来解决这样一个问题,即输出需要连续数值,而LLM会产生离散令牌。
- 直接将LM_Head(.)替换为一个MLP用下面的公式计算:
$$
\hat y =F(u,i)=MLP(h)
$$
- 依然是舍弃LM_Head(.)但是采用了双塔结构来获取用户和项目的representation,并使用距离度量来计算得分:
$$
\hat y =F(u,i)=d(T_u(x_u),T_i(x_i))
$$
- 最后的方法保留LM_Head(.)利用预测概率来计算得分,将用户倾向的二分问题添加到文本描述后,将得分任务变成二进制问题回答问题。
$$
\hat y=\frac{exp(p_{yes})}{exp(p_{yes})+exp(p_{no})}
$$
Item Generation Task
在这项任务中LLM作为一个生成函数$F(u)$来直接通过一次forward就得到item序列。根据是否为LLM提供候选items可以将该任务分为两类:(1)open-set item generation (2)closed-set item generation
- open-set item generation:由于只有用户的信息喂给了LLM而缺乏候选item集合。因此生成的序列和正常的Item pool不能精确匹配。因此除了设计输入prompt模板,微调算法外,item match等后处理也需要被引入来解决幻觉问题。
$$
[\hat{i_k}]{k=1}^N \leftarrow LLM(x_u)\
[i_k]{k=1}^N \leftarrow Match([\hat{i_k}]_{k=1}^N,I)
$$
- closed-set item generation: 先使用一个轻量的检索模型来将items pool缩减到一个较小的候选items序列中,一般大小为20,受限于LLM的内容窗口。LlamaRec采用LRURec作为检索器,之后微调LLaMA2来对预处理的Items进行过滤.
$$
C \leftarrow Pre_filter(u,I)\
[i_k]_{k=1}^N \leftarrow LLM(u,C)
$$
Hybrid Task
得益于LLM的多任务能力,单个的LLM就可以通过不同的Prompt处理生成任务以及scoring任务等。