Harnessing Multimodal Large Language Models for Multimodal Sequential Recommendation (AAAI)
Abstract
现存工作主要关注于将用户的偏好文档转化为文本prompt结合指令调优技术使得LLM能执行推荐任务。
该文首先使用基于MLLM的项目摘要器来提取给定item的图像特征,并将图像转换为文本。然后,采用基于LLM的User摘要器利用循环用户摘要生成策略来捕获用户偏好的动态变化。
Problem Definition
数据集包含User和Item的交互记录,给定用户$u$其交互记录定义为$S_u=[I_u^1,…,I_u^n]$,其中$I^i$代表$u$通过点击购买或者观看交互的第$i$个Item,$n$代表用户的行为序列长度。每一个Item对应一个文本描述$W$和图像$I$。
多模态序列推荐
给定一个$u$和其对应的历史交互记录$S_u$,以及一个候选Item:$I_c$,目的是预测$u$和这个候选Item在下一个交互时的概率(例如,点击的概率)。
Method
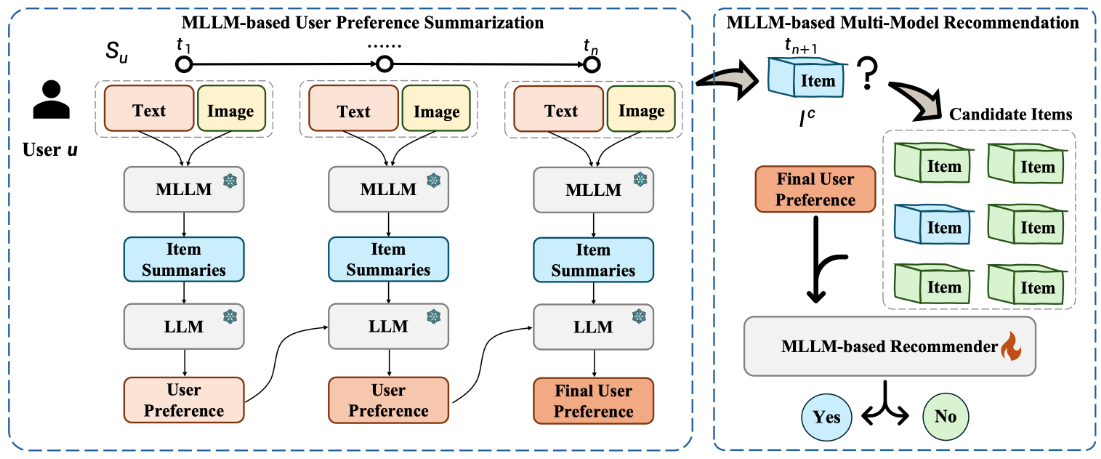
- 起始状态,使用独立的prompts(文本摘要和图像描述prompt)来引导MLLM独立处理这些模态,确保特征和信息能够充分提取到,同时为了保证两个模态的平衡,文本摘要和图像描述的输出被调整到相似的长度。
- 在独立分析两种模态后,使用fusion prompt将来自文本和图像的信息进行整合。
- 将用户的交互序列分成多个块,将长的多模态序列转换为简洁的文本描述。
收到Item整合信息后传递给LLM让其总结用户的偏好,并像RNN式的循环信息,最终获得整个序列的用户偏好和图中一致。
微调基于MLLM的推荐模块
将模型的输出限制为yes or no。通过next token损失来微淘MLLM,使用Lora。
$$
L=-\sum_{i=1}^LlogP(v_i|v_{<i},I)
$$
$v_i$代表prompt的第i个token,L代表prompt的长度,I代表给定的图像。
