一、Online Vocabulary and Offline Vocabulary
Online Vocabulary
这里其实和VLP里的ITC训练一样,抛弃了原先训练yolo时需要固定类和图像,现在就是直接大规模数据集训练。
1)定义
- 训练阶段动态构建的词汇,每个训练批次(batch)都会根据当前样本的标注信息 动态选择 相关的类别名称或名词短语。
- 词汇内容会 随训练数据变化,模型需要实时计算文本嵌入(Text Embeddings)。
2)工作原理
数据加载时:
- 对每个 mosaic 数据增强样本(通常包含 4 张图像),收集所有 正样本名词(出现在图像中的类别)。
- 同时随机采样一些 负样本名词(未出现在当前图像中的类别),以增强模型的判别能力。
词汇构建:
最终词汇表大小限制为 最多 M 个名词(默认 M=80,类似 COCO 的类别数)。
例如,如果当前 batch 包含 “dog”, “cat”, “car”,则词汇可能为:
1
Vocabulary = ["dog", "cat", "car", "person", "tree", ...] # 正样本 + 负样本
文本编码:
- 使用 CLIP 文本编码器 实时计算这些名词的嵌入(Text Embeddings)。
- 这些嵌入会用于计算 区域-文本对比损失(Region-Text Contrastive Loss),优化模型对齐视觉和语言特征。
Offline Vocabulary
(1)定义
- 推理阶段预先编码的固定词汇,用户提前定义好所有可能的类别或描述,并 提前计算 其文本嵌入。
- 模型推理时 无需实时编码文本,直接使用缓存的嵌入,极大提升效率。
(2)工作原理
用户定义词汇:
在实际应用前,用户提供 自定义类别列表,例如:
1
Categories = ["dog", "cat", "person", "car", "traffic light"]
也可以是更复杂的描述,如:
1
Descriptions = ["a red car", "a person wearing glasses"]
离线编码:
- 使用 CLIP 文本编码器 提前计算这些类别的嵌入,并存储为模型的一部分。
推理优化:
- 通过 重新参数化(Reparameterization) 技术,将文本嵌入转换为模型权重(如 1×1 卷积的 kernel),从而完全移除文本编码器的计算。
- 例如:
- T-CSPLayer 的文本引导注意力可以转换为一个固定卷积操作。
- 文本对比头的计算可以直接复用预计算的嵌入。
二、重参数化
文本嵌入作为卷积权重的原理详解
- 数学等价性证明
原始相似度计算
给定:
- 视觉特征 $F \in \mathbb{R}^{H \times W \times D}$
- 文本嵌入 $T \in \mathbb{R}^{C \times D}$
相似度计算:
$S = F \times T^T \in \mathbb{R}^{H \times W \times C}$
1×1卷积等效计算
卷积核权重设置:
$W_{conv} \in \mathbb{R}^{C \times D \times 1 \times 1}, \quad W_{conv}[c,d,0,0] = T[c,d]$
则卷积输出:
$O[h,w,c] = \sum_{d=1}^D F[h,w,d] \cdot W_{conv}[c,d,0,0]$
两者完全等价。
其实可以理解为线性层最好。
二、模型架构
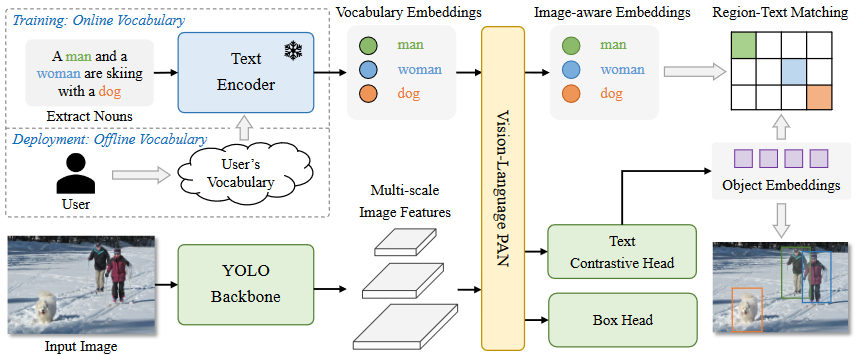
Text Encoder
采用CLIP的文本编码器作为文本encoder,训练方式和上面说过的一样,将文本嵌入和图像类别特征计算相似度。
$s_{k,j} = \alpha \cdot \underbrace{\text{L2-Norm}(e_k)}{\text{归一化物体特征}} \cdot \underbrace{\text{L2-Norm}(w_j)^\top}{\text{归一化文本特征}} + \beta \tag{1}$
- 物体嵌入 $e_k \in \mathbb{R}^D$(第$k$个检测目标的特征)
- 文本嵌入 $w_j \in \mathbb{R}^D$(第$j$个类别的文本特征)
Re-parameterizable Vision-Language PAN
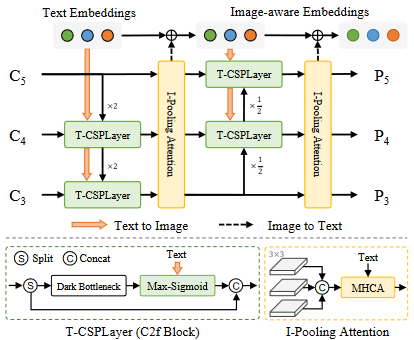
Text-guided CSPLayer
Text-guided CSPLayer是YOLO-World在传统YOLO架构上最重要的创新之一,它本质上是YOLOv8中CSPLayer(也叫C2f模块)的升级版,通过引入文本引导机制,实现了视觉特征语言特征的深度融合。
(1) 核心创新点
传统CSPLayer只处理视觉特征,而T-CSPLayer的创新在于:
a. 增加了文本嵌入输入通道
b. 设计了文本-图像动态交互机制
c. 保持了YOLO原有的高效特性
(2) 关键计算步骤
① 相似度计算:
将图像特征图(H×W×D)与文本嵌入(C×D)做矩阵乘法,得到每个卷积区域位置对应所有文本类别的相似度分数(H×W×C)
② 注意力生成:
对C个类别维度取最大值操作,再通过Sigmoid激活,生成空间注意力图(H×W)
$X_l’=X_l⋅δ(max_{j\in(1..C)}(X_lW_j^T))^T$
$X_lW_j^T$是$H\times W$的矩阵,里面的元素代表相似度。对C个类别取最大值每个位置保留与最相关文本类别的相似度。然后点乘原始图像表征就行。
- Image-Pooling Attention
1. 核心功能
Image-Pooling Attention 是 YOLO-World 中用于增强文本嵌入的视觉感知能力的模块,其核心思想是:让文本特征能够动态感知图像内容,从而提升开放词汇检测的准确性。
2. 计算流程
假设输入为多尺度图像特征 ${X_3, X_4, X_5}$ 和文本嵌入 $W \in \mathbb{R}^{C \times D}$,计算步骤如下:
(1)多尺度特征池化
对每个层级的特征图进行自适应最大池化,统一到固定尺寸(3×3):
$$
\tilde{X}_l = \text{MaxPool}(X_l, \text{output_size}=3) \quad \text{其中} \ l \in {3,4,5}
$$
输出形状:每层得到 $3 \times 3 \times D$ 的特征
示例:
$X_3$ (80×80×256) → 池化后 → 3×3×256
$X_4$ (40×40×512) → 池化后 → 3×3×512
$X_5$ (20×20×1024) → 池化后 → 3×3×1024
(2)特征拼接与扁平化
将多尺度池化结果拼接并展平:
$\tilde{X} = \text{Flatten}(\text{Concat}[\tilde{X}_3, \tilde{X}_4, \tilde{X}_5])$
输出形状:$27 \times D$
(3层级×3×3=27个空间位置,每个位置D维特征)
(3)视觉-文本交互
计算文本嵌入的视觉感知更新:
$W’ = W + \text{Softmax}(W \tilde{X}^\top)\tilde{X}$
Softmax权重表示不同尺度不同图像区域对文本的重要性