Mutual-Modality Adversarial Attack with Semantic Perturbation
introduction
当前的DNN网络虽然取得了巨大的成就,但是一点扰动就可能使他们产生错误的分类。目前的方法大多使用白盒方法进行攻击,但是现实情况往往无法获得模型的权重,因此白盒攻击不如黑盒攻击现实。并且目前的技术主要是通过选择一个合适的替代模型,但是替代模型不但不稳定并且与目标网络的差距往往很大。因此仔细选择一个合适的替代模型就成了一个关键问题。
Method
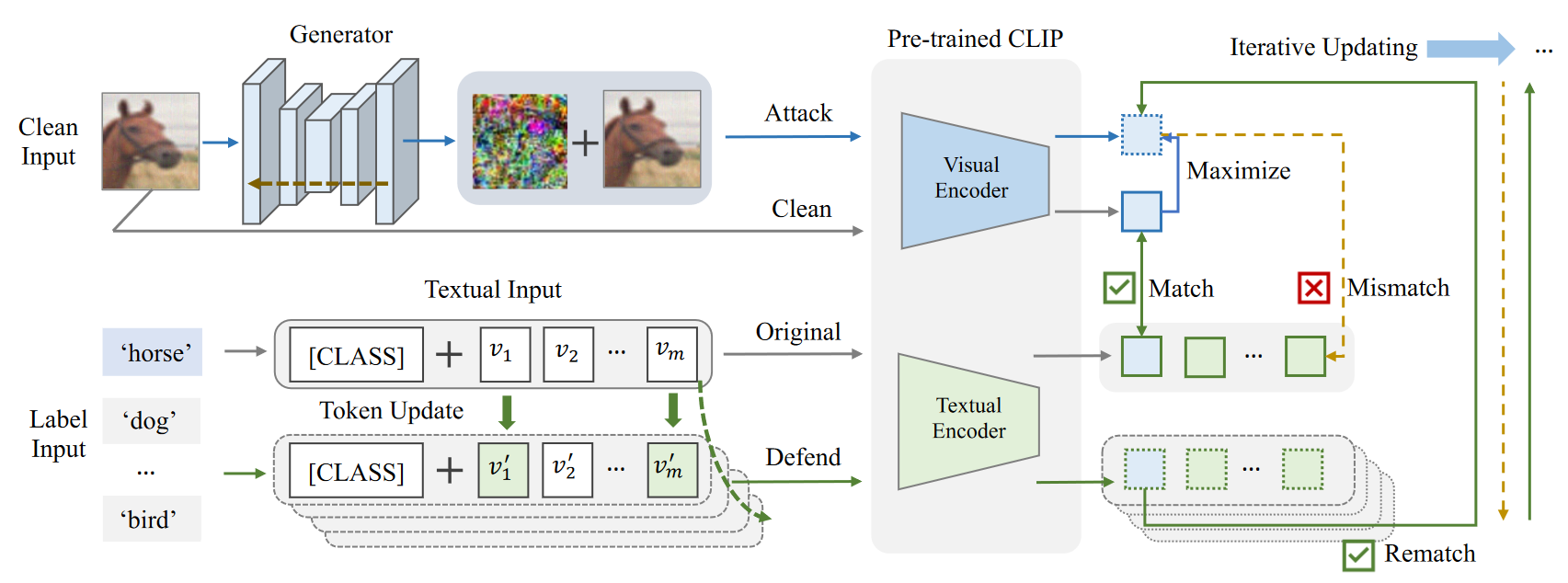
对抗样本$x^{\prime}_i$按照如下公式获取:
$$
x^{\prime}_i=min(x_i+\epsilon,max(\mathcal G(x_i),x_i-\epsilon))
$$
其中$\epsilon$是最大扰动限制。$\mathcal G(x_i)$代表生成的有边界对抗样本。
攻击黑盒模型的目标就是最大化如下公式:
$$
\sum 1 {y^{\prime}\neq y{true}}|y^{\prime} \leftarrow \mathcal{M^p}[\mathcal{G}(x_i)],x_i\in \mathcal{D}^p,\mathcal{M}^p\in \mathcal{M}
$$
$y_{true}$是输入的正确标签,$\mathcal{M}$是目标模型集合。
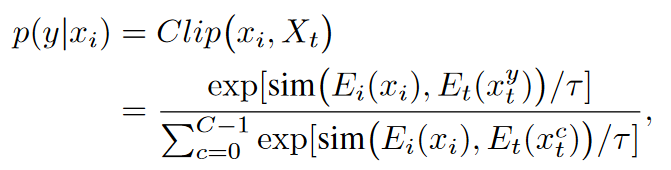
$E_t$是CLIP的文本编码器$E_i$是CLIP的图像编码器,$X_t={x^0_t,x_t^1,…,x_t^{C-1}}$是为每一类标签c生成的文本嵌入。
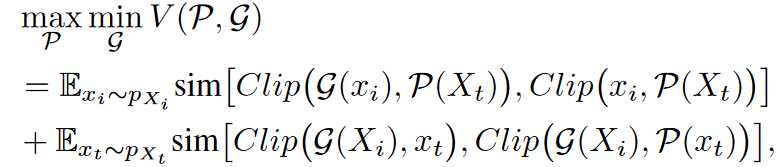
$\mathcal{P}(.)$是文本输入的提示调整函数。
- 优化$\mathcal{G}$是通过最小化干净图像和对抗图像的余弦相似度实现。
- 优化$\mathcal{P}$是通过调整$\mathcal{P}(x_t)$使其能重新和对抗图像匹配上。
- 通过迭代训练获得一个扰动网络$\mathcal{G}$
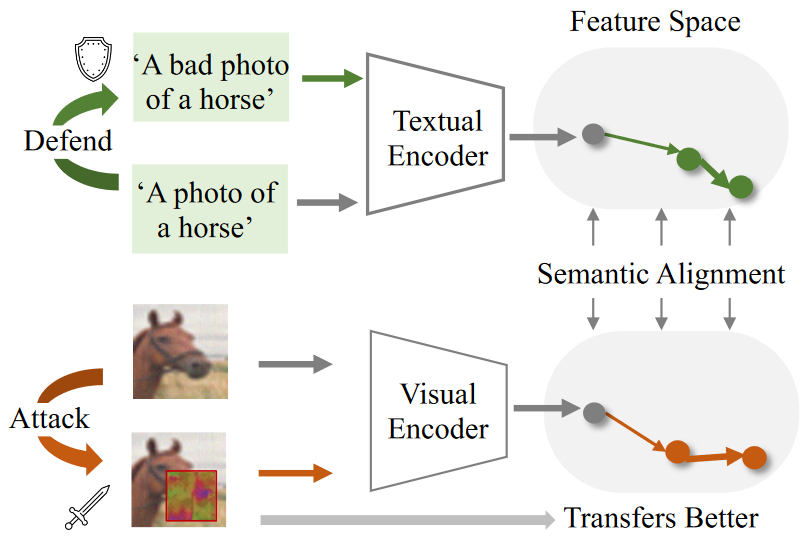
Visual Attack with Semantic Perturbation
一
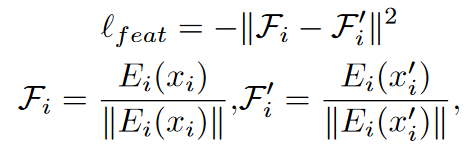
这一步通过最大化CLIP图像编码器所提取出的扰动图像特征和干净特征的相似度来实现,使用MSE损失。
二
通过一个给定的prompt和标签来构造文本输入,然后使用CLIP的文本编码器提取表征按照如下公式进行最大化特征
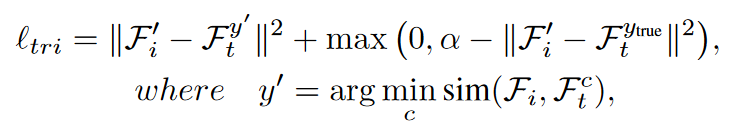
先选择出与干净文本输入最不接近的扰动文本,拉近扰动的图像特征和它的距离,$\alpha$用于设定扰动的图像表征和正确答案的距离不能过低也不会过高。
三
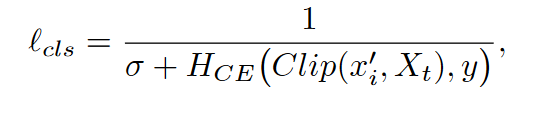
分类损失,$H_{CE}(.)$是标准交叉熵损失,Clip(.)是输出的概率
Textual Defense with Prompt Updating
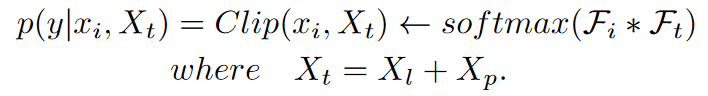
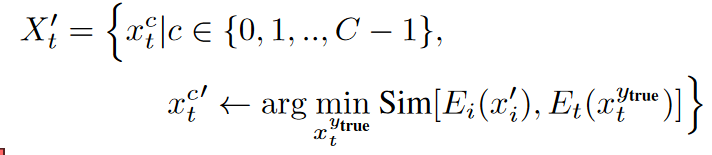
- $X_l=<CLASS(c)>,X_p={v_1,v_2,…,v_m}$。文本输入其实由这两部分组成,即标签和提示模板,在更新时按照如下方式更新:
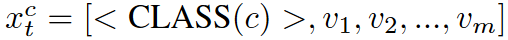
- 只更新提示模板,通过最大化扰动图像嵌入和这个文本的距离找到最合适的提示模板。(相当于每一个lable一个句子,然后只优化每个句子后面的模板部分)由于直接学习每一个文本的最佳标记是不合适的,因此通过计算突出得分,选取合适的单词:
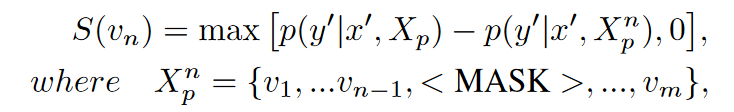
(Generating Natural Language Adversarial Examples through Probability Weighted Word Saliency)
- 将其中得分超过阈值的token放到一个集合中,从一个候选集合中替换更新集合的单词(这里是使用GPT-2生成候选单词):
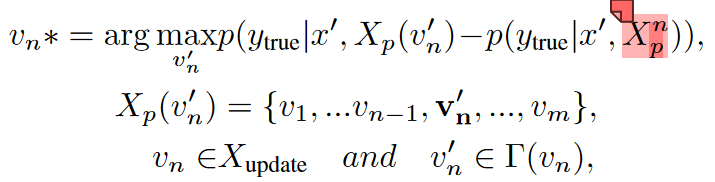
这里应该是括号位置错了,目的应该是替换后的句子的正确概率和mask句子的概率之差的最大,因为差的越大说明这个替换越接近,也就是防御了。
Experience
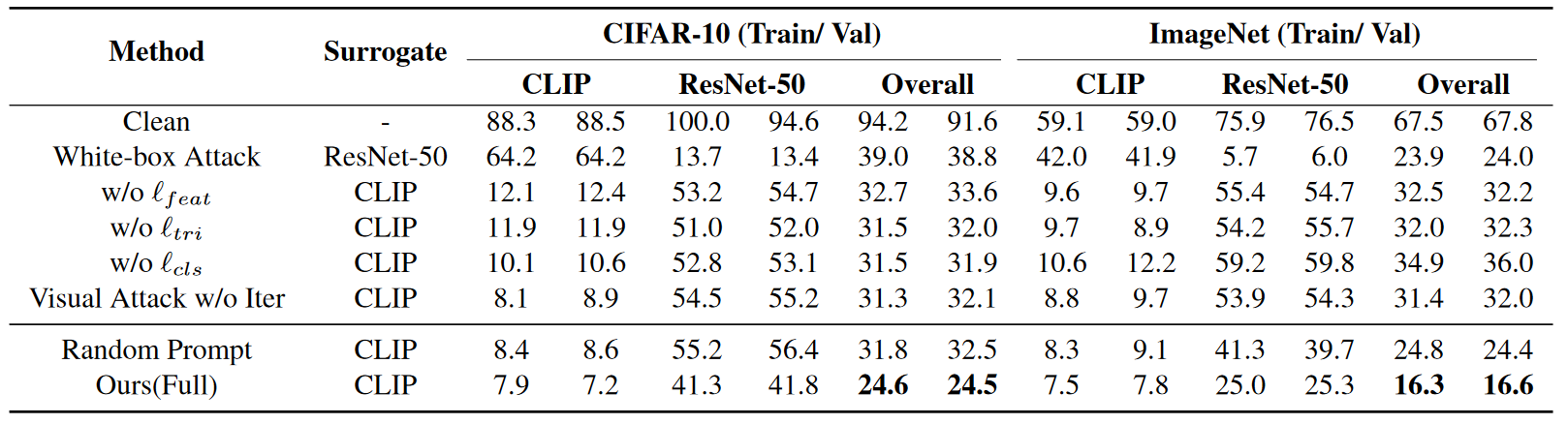
- 消融实验