FDA
introduction
在攻击Deep Neural Networks(DNN)时,大多数现存工作的做法是通过优化网络的softmax或者pre-softmax的输出来进行攻击的,但这样做会导致网络每一层所提取到的特征不会被完全打破,而保留一些特征。如下图(用feature inversion技术可视化):

因此文本提出FDA攻击来解决这一问题。
Method
FDA 会产生扰动,目的是以有原则的方式破坏网络各层的特征。这将导致深层特征的破坏,进而降低网络的性能。
将对抗样本$\tilde{x}$定义为如下形式:
$$
argmax(f(\tilde{x}))\ne y_{GT} \quad & \quad d(x,\tilde{x})<\epsilon
$$
其中分类器$f:x\in R^m \rightarrow y \in Y^c$。$x$是$m$维的输入,$y$是$c$维的pre-softmax输出,$y_{GT}$是标准答案。
全新的评价指标
只看愚弄率并不能反映攻击的全貌。一方面,PGD-ML 等攻击可能会将标签翻转到语义相似的类别中,另一方面,PGD-LL 等攻击可能会将标签翻转到非常不同的类别中,同时仍保留原始标签的高(相对)概率。因此提出如下两个指标
- New Label Old Rank(NLOR)
- Old Label New Rank(OLNR)
将C-way 分类器输出的c类softmax输出作为每一类的置信度,使用降序将他们进行排序,将攻击前的网络预测视为旧标签,攻击后的网络预测视为新标签。
在大多数攻击中,旧标签的等级会从 1 变为 “p”。旧标签的新等级 “p “被定义为 OLNR。此外,攻击后,新标签的等级将从 “q “变为 1。“q”被定义为NLOR
攻击方法
$$
\mathcal{L}(l_i)=D({l_i(\tilde{x}{N_j})|N_j \notin S_i})-D({l_i(\tilde{x}{N_j})|N_j \in S_i})
$$
其中,$l_i$代表第$i$层网络,$l_i(\tilde{x}){N_j}$表示 $l_i(\tilde{x})$ 的第 $N_j$ 个值,$S_i$ 表示支持当前预测的激活集,D 是激活集$l(\tilde{x}){N_j}$的单调递增函数。我们将 D 定义为输入$l_i(\tilde{x})$的$l_2$正态。
$$
S_i={N_j|l_i(x)_{N_j}>C}
$$
C是一种中心趋势的度量,本文使用$spatial-mean(l_i(x))=C(h,w)$(跨通道平均)
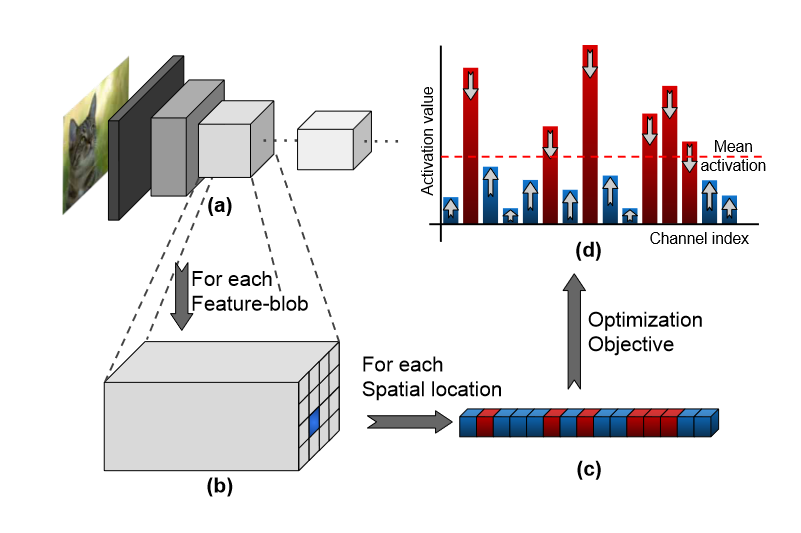
可以从(d)图看出其实现就是大的值降低,低的值增大。将两个公式结合变为如下形式:
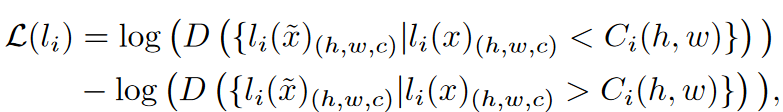
最终损失函数定义为如下形式:
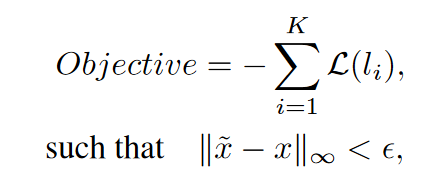
Experience
相似度
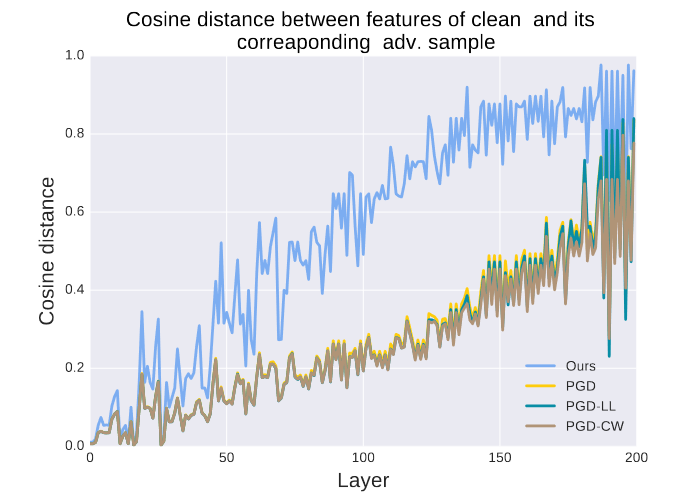
上面展示了在每一层中对抗图像和原始图像的不相似度(图名应该写错了)。
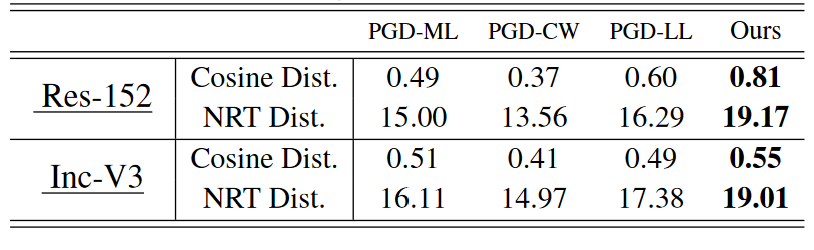
我们还测量了Normalized Rank Transformation (NRT) distance。NRT 距离表示第 k 个有序统计量 ∀ k 的秩的平均移动。NRT 距离测量法的主要优势在于其对异常值的稳健性。
愚弄率,NLOR,OLNR
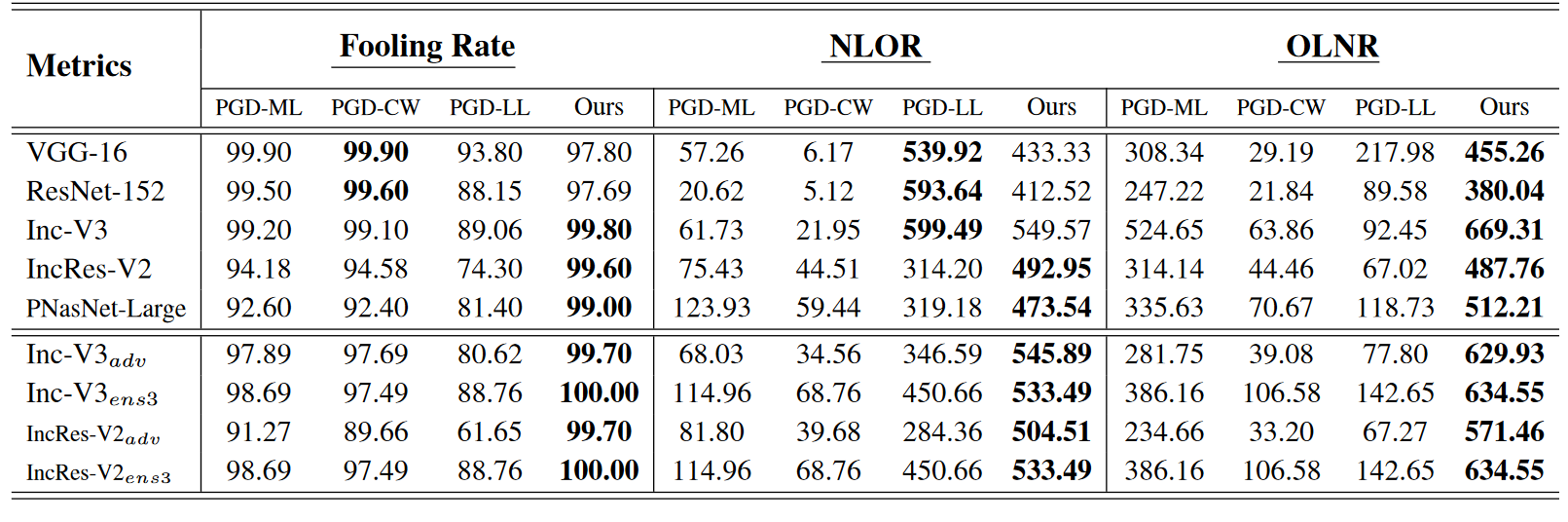
测试了提出的方法在各种模型上的表现,下面的是对抗训练过的模型。
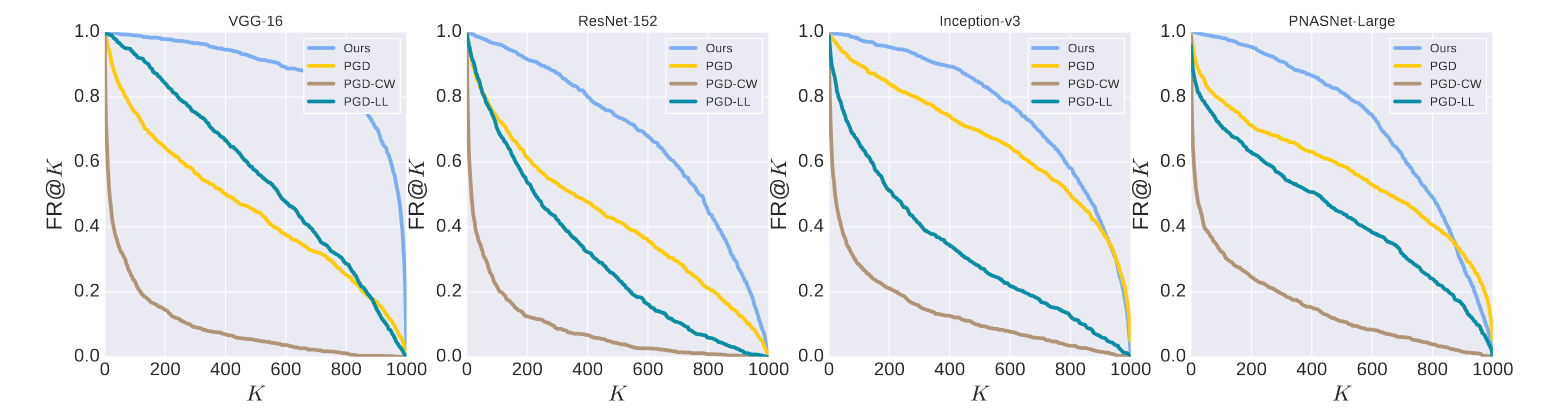
结合TOP@K准确率的愚弄率,应该就是1-前K个结果出现正确阶段的比例因此K值增大愚弄率会下降因为不好骗了。
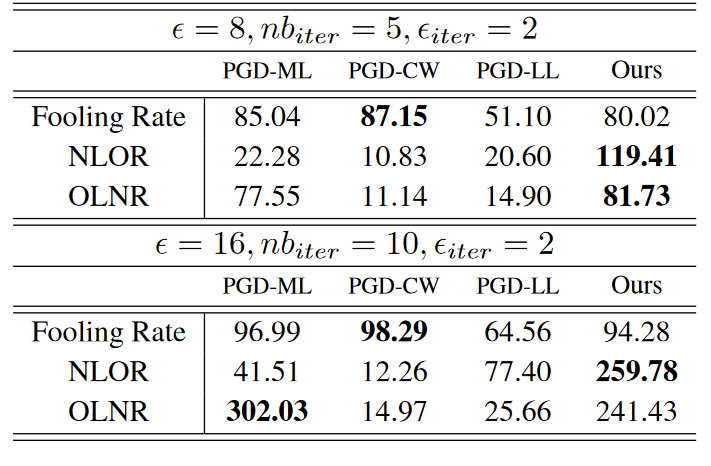
这个是经过Adversarial-logitpairing (alp) based adversarial training的模型
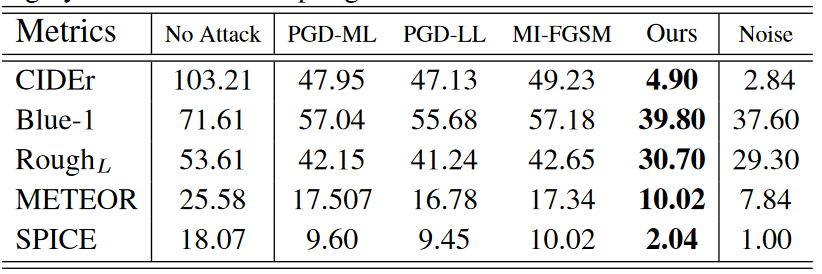
上表展示了对字幕生成的攻击效果,右侧是纯白噪声的效果。