VQAttack

introduction
- 现在多模态模型遵循 预训练-微调范式。在进行VQA任务时,微调的数据在预训练中没有见到过,并且微调的模型结构可能与预训练模型有差异。导致可转移性上有问题。
- 单模态攻击比较成熟但是对于连续图像数值和离散文本的多模态攻击并没有充分探究。
结构
使用一个预训练模型去生成图像和文本的对抗样本,在各种微调模型中测试。这里的微调模型是任意的,黑箱的。
目标
用$F$ 来代表预训练模型,$S$ 代表下游微调模型,在预训练模型上用干净的$(I,T)$ 图像文本对生成对抗图像文本对$(\hat{I},\hat{T})$
使得 $S(\hat{I},\hat{T}) \notin Y$ ,由于正确答案不一定是一个所以$Y$是正确答案的集合。
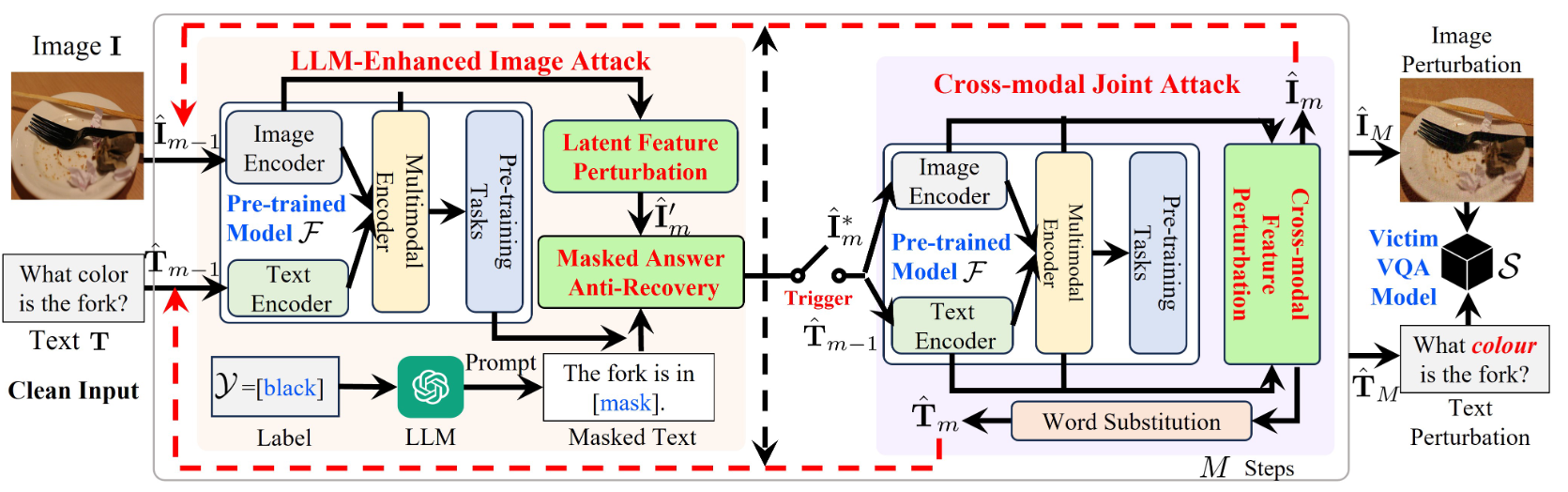
算法流程

损失函数
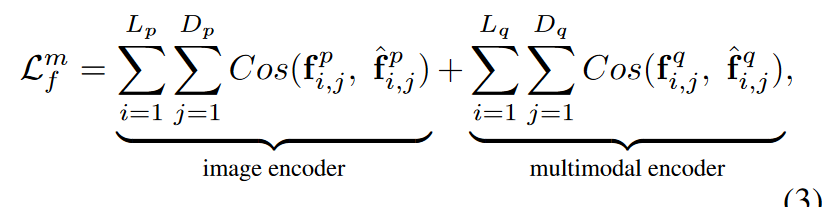
和VlAttack类似,其中$ L_p$ 和$ L_q $分别表示图像编码器和多模态编码器的层数。$D_p$ 和$ D_q$ 分别表示图像编码器和多模态编码器的输入标记数。对于图像编码器,输入标记是图像片段;而多模态编码器则将图像片段和文本词的表示作为输入标记。$f^p_{i,j}$和$f^q_{i,j}$ 是第 i 层第 j 个标记的输出特征表示向量
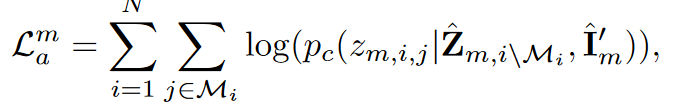
将句子,正确标签和prompt传给chatgpt来生成扰动句子,并将正确标签位置的单词mask掉,N代表正确标签个数,由于正确的标签不一定是一个单词因此生成时,一个token一个token生成,让其概率最小。$z_{m,i,j}$代表第i个标签句子的第j个位置token。
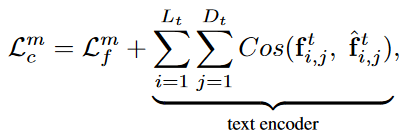
算法总结
对于图像应该是分两步进行梯度优化,第一步直接根据原始图像和扰动图像的
- 联合攻击
联合扰动中,使用NLTK工具包过滤掉所有停滞词得到一个集合{$t_i|i\in W$},然后用BERT-Attack对这i个标记按照相似性生成前k个候选词。得到一个候选序列$C = {c_{i,j}|1\le j \le K}_{i\in W}$
由于单词在文本编码器中应该是token形式的,因此根据$L^m_c$损失可以得到第i个token的梯度,使用这个梯度和其的单词嵌入$E(t_i)$就可以得到估计更有希望的候选词 $E(\hat{t_i})=E(t_i)+\delta L_c^m(t_i)$ ,从$t_i$的候选词中找到与$E(\hat{t_i})$ 余弦相似度最大的单词即可。
$y_{i,j}=\cos(E(\hat{t_i}),E(c_{i,j}))$
用上述公式对候选词进行排序得到$R(c)$,用最大的词替换句子中的单词,检查其是否满足$\cos(U(\hat T^{\prime}_{m-1}),U(T))>\sigma$ 满足就替换并在$R(c)$中删除这个单词的所有同义词然后移至下一个信息词