BertAttack
Introduction
原先方法
- 原先的攻击方式基于特定的规则,这样就不能同时保证生成的对抗样本语义一致并流畅。
- 方法较为复杂
本方法
- 使用Bert作为语言模型去生成对抗样本。高效
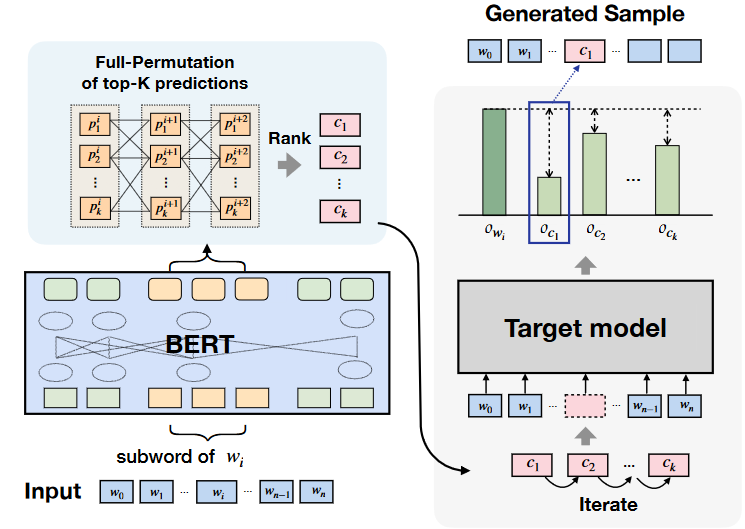
算法
首先找到句子中重要性大的单词:
$o_y$ 是模型预测概率 $S_{/w_i} = [w_0,…,w_{i-1},[MASK],w_{i+1},…]$
$$
I_{wi}=o_y(S) - o_y(S_{/w_i})
$$
所以最后值越大的就代表这个单词最易收到攻击,因为将其mask掉后概率很低。(代码里用的是[UNK]标记)
1 | masked_words.append(words[0:i] + ['[UNK]'] + words[i + 1:]) |
用语义连贯的单词去替换这些单词:
这里并不会将i位置的单词mask掉然后让其预测,因为会产生这样的问题:
”I like the cat.” 将cat位置mask掉很难生成cat,因为生成”I like the dog.”同样是顺畅的。(不过按照代码实现的角度确实应该是mask了)
计算代价大
因此将原始句子$S=[w_0,w_1,…]$分词成sub-word $H=[h_0,h_1,…]$ 将H输入ML model中得到概率P,这里不会直接取最大值而是取前K个值作为每一个位置的K个替换词。也就是最后生成一个$P^{\in n×K}$ 的矩阵,其中第i行代表第i个单词的前k位替换词。
参数解析
- sub-word:例如一个句子[‘i’,’like’,’dog’],sub-word就是将’dog’这样的单词进行第一次分词,BERT采取的BPE来进行分词,因此结果可能导致一个单词分词后成两个token。针对这种情况本文分开进行处理:
- single word:将K个候选词进行第一次过滤去除其中的停顿词。(不同任务清理的也不同)替换后进行测试是否攻击成功。
- sub-word:如果一个单词被分成$[h_0,h_1,…,h_t]$ ,那么对应P部分该单词的token候选应该是$R\in t*K$ ,可以得到$K^t$个token组合将其转换成正常单词后计算困惑度得到前K个组合,从而找到合适的子词组合。
- sub-word:例如一个句子[‘i’,’like’,’dog’],sub-word就是将’dog’这样的单词进行第一次分词,BERT采取的BPE来进行分词,因此结果可能导致一个单词分词后成两个token。针对这种情况本文分开进行处理:
代码实现
获得可替换词P:
1 | sub_words = ['[CLS]'] + sub_words[:max_length - 2] + ['[SEP]'] |
总览

实验
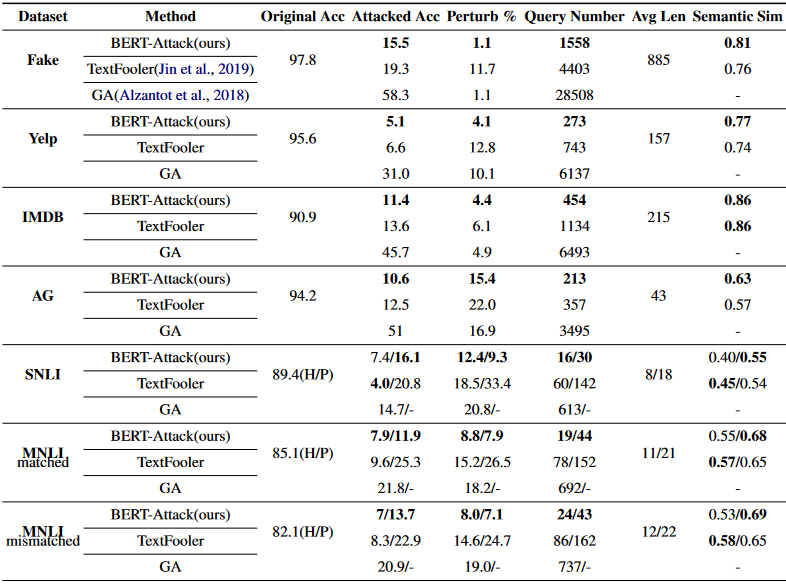
- Perturb:扰动率,越小说明语义一致性越强
- Original Acc 和 Attacked Acc:原始成功率和攻击后成功率,两者对比
- Query Number:黑盒模型查询次数
- Avg Len:句子平均长度,越长理论上需要查询次数越多。
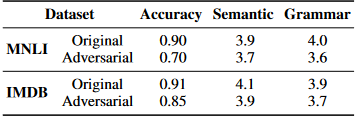
人工评价:
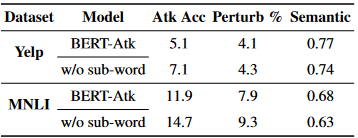
消融和讨论
- K值选取:


- 子词级攻击
- 可转移性,对抗训练

