InstructBLIP
Introduction
本文是基于预训练的BLIP-2模型对视觉语言指令调优进行研究。
通过在自然语言指令描述的各种任务上微调大语言模型,指令调优使模型能够遵循任意指令。然而由于额外添加的来自多种领域的视觉输入,视觉语言的任务和NLP任务比起来更加的多样。这对统一模型提出了更大的挑战,该模型应该泛化到不同的视觉语言任务,其中许多任务在训练期间是看不见的。大多数以前的工作可以分为两种方法。
- 第一种方法是多任务学习 ,将各种视觉语言任务制定为相同的输入输出格式。然而,我们凭经验发现,没有指令的多任务学习不能很好地推广到未见过的数据集和任务。
- 第二种方法是使用额外的视觉组件拓展预训练好的LLM,用图像注释对去训练视觉组件。然而,这些数据太有限,无法广泛推广到需要视觉描述之外的视觉语言任务。
本文主要贡献:
- 我们对视觉语言指令调整进行了全面、系统的研究。我们将 26 个数据集转换为指令调整格式,并将它们分为 11 个任务类别。我们使用 13 个保留数据集进行指令调整,使用 13 个保留数据集进行零样本评估。此外,我们保留了四个完整的任务类别,用于任务级别的零样本评估。详尽的定量和定性结果证明了 InstructBLIP 在视觉语言零样本泛化方面的有效性。
- 我们提出了指令感知视觉特征提取,这是一种新颖的机制,可以根据给定的指令进行灵活且信息丰富的特征提取。具体来说,文本指令不仅提供给冻结的 LLM,还提供给 Q-Former,以便它可以从冻结的图像编码器中提取指令感知的视觉特征。此外,我们提出了一种平衡采样策略来同步跨数据集的学习进度。
- 我们使用两个 LLM 系列评估并开源了一套 InstructBLIP 模型:1)FlanT5 [7],一个从 T5 [34] 微调的编码器-解码器 LLM; 2) Vicuna [2],从 LLaMA [41] 微调的仅解码器的 LLM。 InstructBLIP 模型在各种视觉语言任务上实现了最先进的零样本性能。此外,当用作单个下游任务的模型初始化时,InstructBLIP 模型可实现最先进的微调性能。
指令微调
为了确保指令调优数据的多样性,同时考虑其可访问性,我们收集了一组全面的公开可用的视觉语言数据集,并将它们转换为指令调优格式。如图2所示,最终集合涵盖11个任务类别和26个数据集,包括图像字幕,具有阅读理解的图像字幕,视觉推理,图像问答,基于知识的图像问答,具有阅读理解的图像问答,图像问题生成(改编自 QA 数据集),视频问答 、视觉会话问答、图像分类和LLaVA-Instruct-150K 。
对于每一个任务用自然语言制作10-15个不同的指令模板。对于本质上偏向于短响应的公共数据集,我们在一些相应的指令模板中使用诸如“短”和“简要”之类的术语,以降低模型过度拟合而始终生成短输出的风险。
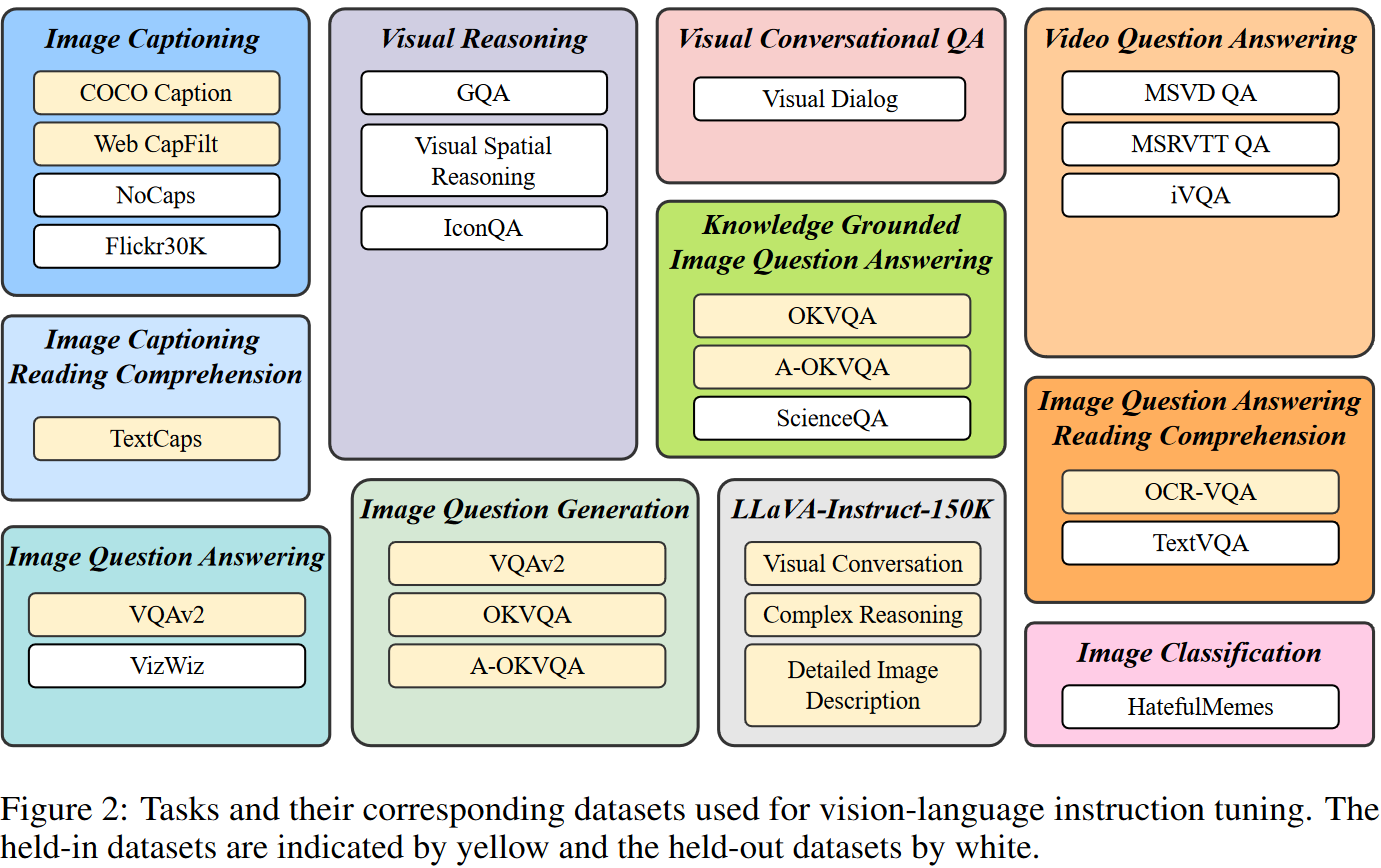
我们使用保留数据集的训练集进行指令调整,并使用它们的验证或测试集进行held-in评估。
对于held-out评估,我们的目标是了解指令调优如何提高模型在未见过的数据上的零样本性能。我们定义两种类型的保留数据:
- 在训练期间未暴露给模型的数据集,但其任务存在于保留集群中;
- 在训练期间完全看不到的数据集及其相关任务。
由于保留数据集和保留数据集之间的数据分布变化,解决第一类保留评估并非易事。对于第二种类型,我们完整地保留了几项任务,包括视觉推理、视频问答、视觉会话 QA 和图像分类。
Instruction-aware Visual Feature Extraction
现有的zero-shot 图像到文本生成方法在提取视觉特征时使用与指令无关的方法。这会导致无论任务是什么,输入到LLM中的都是一组静态视觉表示。
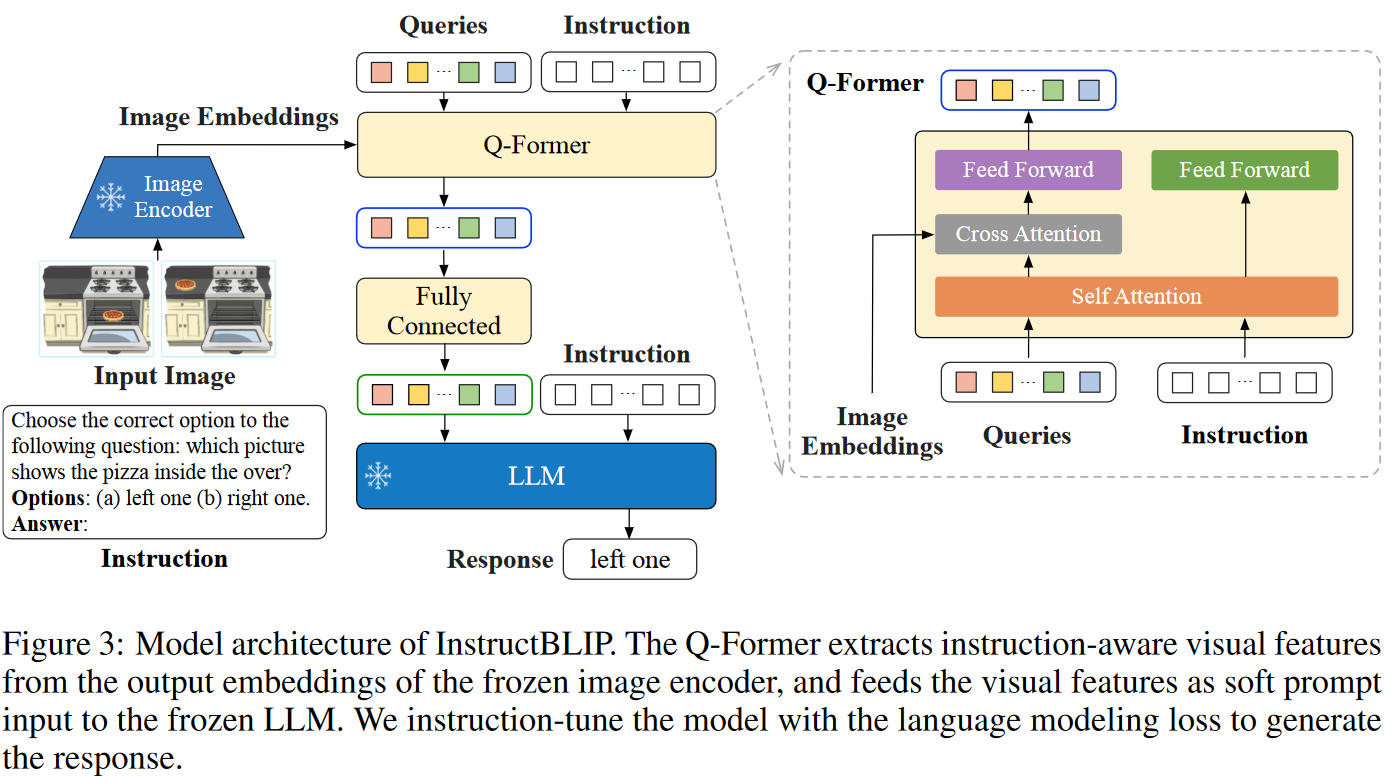
InstructBLIP 的架构。与 BLIP-2 类似,InstructBLIP 利用 Q-Former 从冻结图像编码器中提取视觉特征。 Q-Former 的输入包含一组 K 个可学习的查询嵌入,它们通过交叉注意力与图像编码器的输出交互。 Q-Former 的输出由 K 个编码视觉向量组成,每个查询嵌入一个,然后经过线性投影并馈送到冻结的 LLM。
训练
与 BLIP-2 一样,Q-Former 使用图像描述数据进行指令微调前分两个阶段进行预训练。
- 第一阶段使用冻结的图像编码器对Q-Former和进行视觉语言表征学习。
- 第二阶段采用 Q-Former 的输出作为软视觉提示,用于使用冻结的 LLM 生成文本。
预训练后,使用通过instruction-tuning 对 Q-Former 进行微调,其中 LLM 接收来自 Q-Former 的视觉编码和任务指令作为输入。
超参数
使用 LAVIS 库进行实施、培训和评估。所有模型都经过指令调整,最多 60K 步,我们每 3K 步验证一次模型的性能。对于每个模型,选择一个最佳检查点并用于对所有数据集进行评估。我们对 3B、7B 和 11/13B 模型分别采用 192、128 和 64 的批量大小。
- 优化器:
使用 AdamW 优化器,β1 = 0.9,β2 = 0.999,权重衰减为 0.05。
- 学习率
在最初的 1,000 个步骤中对学习率进行线性预热,从 10−8 增加到 10−5,然后进行余弦衰减,最小学习率为 0。
平衡训练数据集
由于训练数据集数量庞大并且每个数据集的大小有很大的不同,均匀混合他们可能会导致模型对较小的数据集过拟合,对于更大的数据集拟合不足。
假如有D个数据集,他们的大小分别是$(S_1,S_2,…,S_D)$,那么训练期间从数据集d中选择数据的概率为:
$$
p_d=\frac{\sqrt{S_d}}{\sum_{i=1}^D{\sqrt{S_i}}}
$$
在这个公式基础上本文对某些数据集的权重进行手动调整。尽管数据集的任务和大小相同,但需要不同程度的训练强度。
推理
在推理过程中,我们采用了两种略有不同的生成方法对不同的数据集进行评估。
- 对于大多数数据集,如图像标题和开放式 VQA,我们会直接提示经过指令调整的模型生成响应,然后将其与地面实况进行比较以计算指标。
- 另一方面,对于分类和多选 VQA 任务,我们沿用了以前的研究成果,采用了词汇排序法。具体来说,我们仍然促使模型生成答案,但将其词汇量限制在候选列表中。然后,我们计算每个候选词的对数似然,并选择数值最大的一个作为最终预测结果。这种排序方法适用于 ScienceQA、IconQA、A-OKVQA(多选)、HatefulMemes、Visual Dialog、MSVD 和 MSRVTT 数据集。
对于二分类,为了利用自然文本中的词频,我们将正面和负面标签扩展为范围稍广的动词集(例如,正面类为 yes 和 true;负面类为 no 和 false)。
对于video question-answering task,我们对每段视频使用四个统一采样的帧。图像编码器和 Q-Former 分别对每一帧进行处理,提取的视觉特征在输入 LLM 之前进行串联。
实验
我们首先使用下图中提供的说明在 13 个held-out数据集上评估 InstructBLIP 模型。我们将 InstructBLIP 与之前的 SOTA 模型 BLIP-2 和 Flamingo 进行比较。如表 1 所示,我们在所有数据集上实现了新的零样本 SOTA 结果。 InstructBLIP 在所有LLM中均大幅超越其原始骨干 BLIP-2,
评估instruction

实验结果
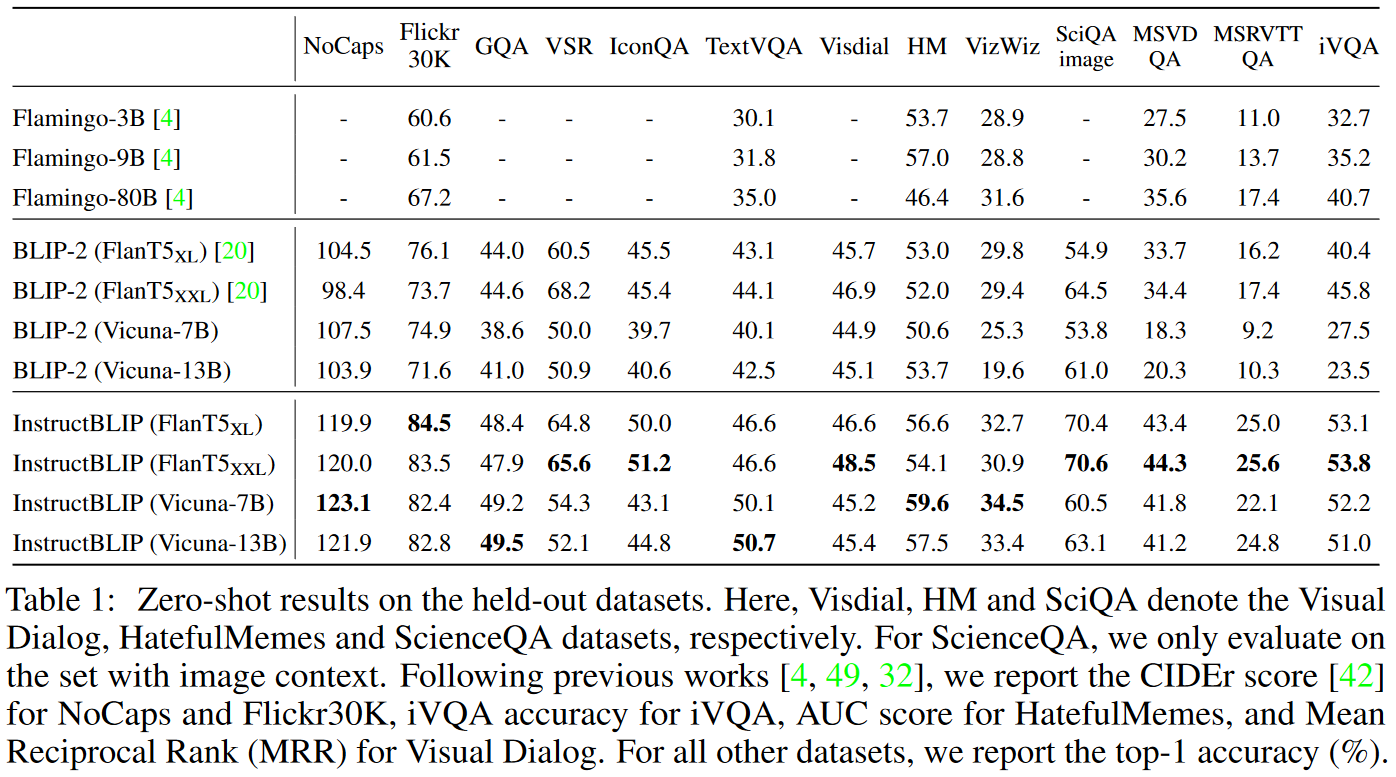
与 BLIP-2 FlanT5XL 相比,InstructBLIP FlanT5XL 的平均相对改进为 15.0%。此外,指令调优增强了对视频 QA 等看不见的任务类别的零样本泛化。尽管从未使用时态视频数据进行过训练,但 InstructBLIP 在 MSRVTT-QA 上相对于之前的 SOTA 实现了高达 47.1% 的相对改进。最后,我们具有 4B 参数的最小 InstructBLIP FlanT5XL 在所有六个共享评估数据集上均优于 Flamingo-80B,平均相对改进为24.8%。
对于Visual Dialog dataset,我们选择报告标准化贴现累积增益 (NDCG) 指标的平均倒数排名 (MRR)。这是因为 NDCG 倾向于通用且不确定的答案,而 MRR 更倾向于某些响应 [32],从而使 MRR 更好地与零样本评估场景保持一致。
消融实验:
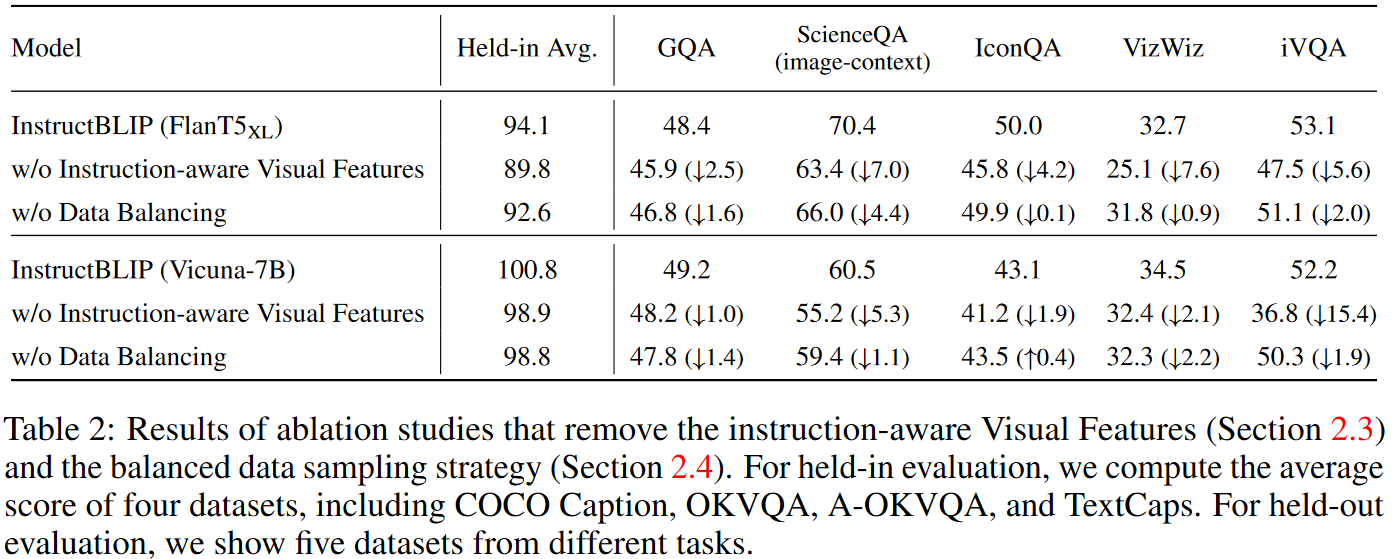
为了研究指令感知视觉特征提取和平衡数据集采样策略的影响,我们在指令调整过程中进行了消融研究:
- 消除视觉特征中的指令感知会显着降低所有数据集的性能。在涉及空间视觉推理(例如 ScienceQA)或时间视觉推理(例如 iVQA)的数据集中,性能下降更为严重,其中 Q-Former 的指令输入可以引导视觉特征关注信息丰富的图像区域。
- 数据平衡策略的删除会导致训练不稳定和不均匀,因为不同的数据集在截然不同的训练步骤中达到峰值性能。多个数据集缺乏同步进度会损害整体性能。
Instruction Tuning vs. Multitask Learning