NExT-GPT Any-to-Any Multimodal LLM
Introduction
- 问题:目前的多模态大模型面临着只能处理输入端的多模态理解问题,而不能去用多模态生成内容。
人类感知和与他人交流总是通过多种模态,开发一种any-to-any的能接受和传递任意模态的多模态大模型对于human-level级的AI变得尤其重要。
- 本文提出NExT-GPT解决生成端的多模态问题,用多模态适配器连接上LLM和不同的扩散解码器。通过使用现存的已经经过训练的表现良好的编码器和解码器,NExT-GPT可以只用微调只占1%参数的某些投影层。
model

目前一种值得注意的方式是使用适配器将其他模态的预训练编码器和文本大模型对齐。但是这样的做法只关注输入端的多模态内容理解缺乏输出文本外的多种模态内容能力。
- 我们只考虑对输入投影层和输出投影层进行局部微调,编码侧对齐以 LLM 为中心,解码侧对齐以指令为中心。
模型包含3种主要层次:
encoding stage:这里使用跨6种模态的统一高性能编码器ImageBind。
LLM understanding and reasoning stage:使用Vicuna,将不同模态的表征作为输入,并对输入进行语义理解和推理。
输出包括:
- 直接的文本响应
- 每种模态的信号标记用于指示解码层是否生成多模态内容以及生成什么内容
decoding stage:基于变换器的输出投影层接收来自 LLM的带有特定指令的多模态信号,将信号标记表征映射为后续多模态解码器可以理解的表征。
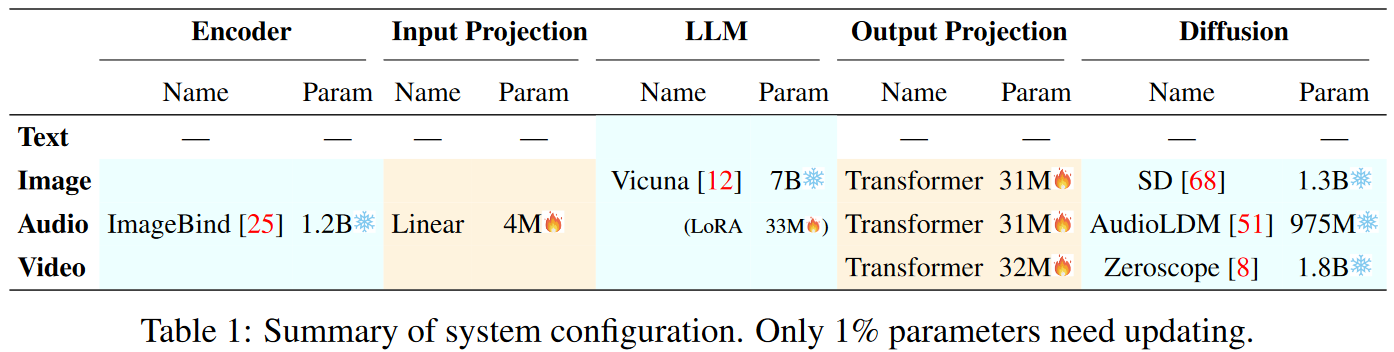
对齐
输入端
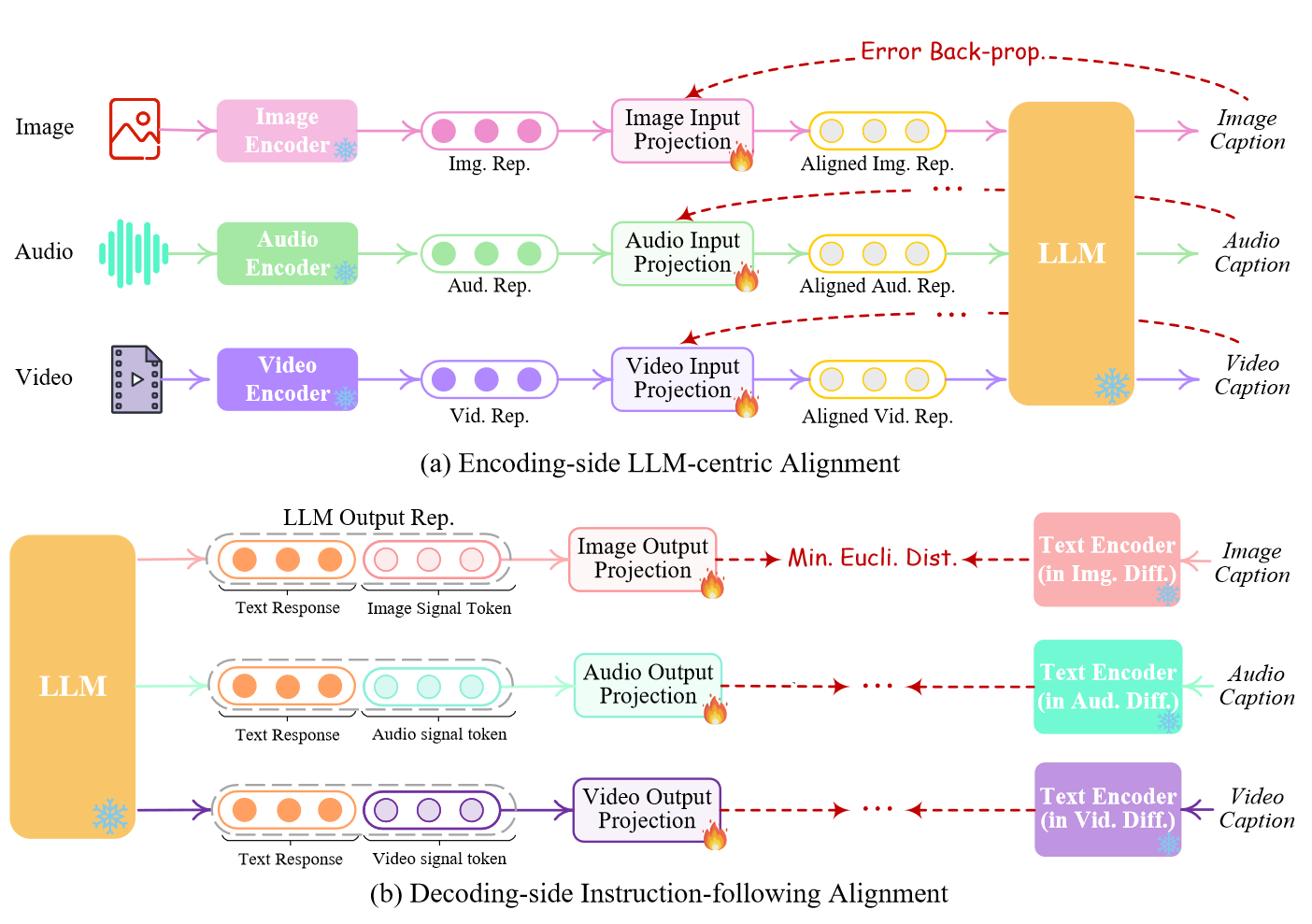
本文考虑将不同的输入模态特征和文本特征空间对齐,这样表征可以被LLM内核识别。输入多模态-文本对并将LLM生成的标题与标准标题进行比对。
解码端指令对齐
每个扩散模型和 LLM 之间执行全面的对齐过程将带来巨大的计算负担。作为替代方案,我们在此探索一种更高效的方法,即解码侧指令跟随对齐,如图 3(b) 所示。具体来说,由于各种模式的扩散模型仅以文本标记输入为条件。在我们的系统中,这种条件与来自 LLM 的模态信号标记有很大差异,这导致扩散模型在准确解释来自 LLM 的指令方面存在差距。因此,我们考虑最小化 LLM 的模态信号标记表示(在每个基于 Transformer 的项目层之后)与扩散模型的条件文本表示之间的距离。由于只使用了文本条件编码器(扩散骨干被冻结),因此学习仅仅基于纯字幕文本,即不需要任何视觉或音频资源。这也确保了训练的高度轻量化。
Modality-switching Instruction Tuning
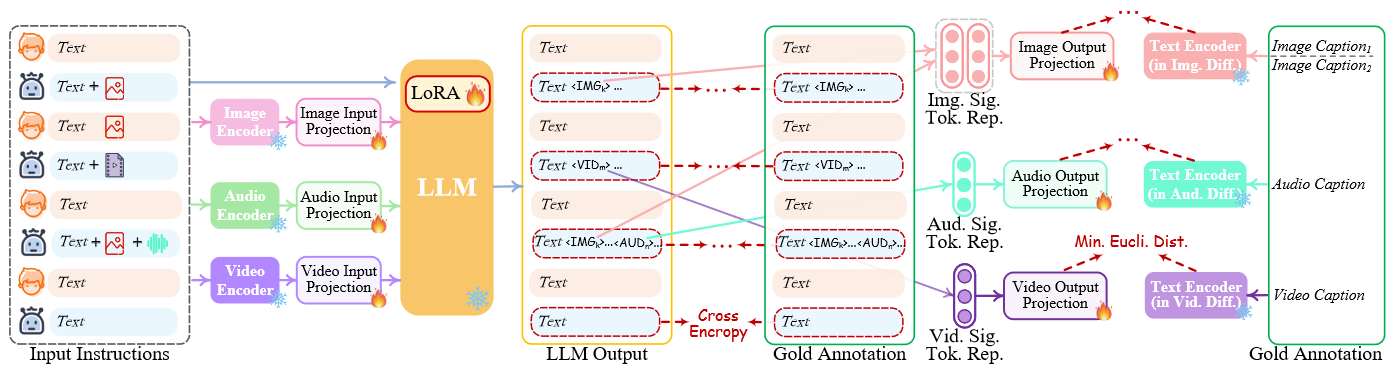
尽管编码和解码两端都与 LLM 保持一致,但在实现使整个系统能够忠实地遵循和理解用户指令并生成所需的多模态输出这一目标方面仍存在差距。为了解决这个问题,进一步的指令调整(IT)被认为是提高 LLM 的能力和可控性所必需的。IT 涉及使用”(输入,输出)”对整个 MM-LLM 进行额外训练,其中 “输入 “表示用户指令,”输出 “表示符合给定指令的所需模型输出。在技术上,我们利用 LoRA ,使 NExT-GPT 中的一小部分参数在 IT 阶段与两层投影同时更新。 当一个 IT 对话样本输入系统时,LLM 会重建并生成输入的文本内容(并以多模态信号标记表示多模态内容)。优化基于金注释和 LLM 的输出。除了 LLM 调整外,我们还对 NExT-GPT 的解码端进行了微调。我们将输出投影编码的模态信号标记表示与扩散条件编码器编码的黄金多模态字幕表示相一致。因此,综合调整过程更接近与用户进行忠实、有效互动的目标。