Visual Instruction Tuning
Instruction
利用机器生成的instruction-following data对大型语言模型(LLM)进行指令调整,提高了新任务中的零拍能力,但这一想法在多模态领域的探索较少。
在本文中,提出了 visual instruction-tuning,这是首次尝试将指令调整扩展到多模态空间,为构建通用视觉助手铺平了道路。本文做出了以下贡献:
- Multimodal instruction-following data. 其中一个主要挑战是缺乏视觉语言教学数据。我们提出了一种数据重组观点和管道,利用 ChatGPT/GPT-4 将图像-文本对转换为适当的instruction-following格式。
- 大型多模态模型。我们开发了一个大型多模态模型(LMM),将 CLIP [36] 的开放集视觉编码器与语言解码器 LLaMA 相连接,并在生成的视觉语言教学数据上对它们进行端对端微调。我们的实证研究验证了使用生成数据进行 LMM 指令调整的有效性,并为构建通用指令跟随视觉代理提出了实用建议。利用 GPT-4,我们在ScienceQA 多模态推理数据集上取得了一流的性能。
GPT辅助的instruction-following data构建
1. 一种天真的方式去将图像文本对拓展为instruction-following:Xq参见表8
Human : Xq Xv
Assistant : Xc
其中Xq是question,Xv是image,Xc是caption。
但是这种简单的构建方式在instruction和response上都缺乏多样性和深度推理。
2. 为了解决这个问题本文利用纯文本的GPT-4或者ChatGPT作为teacher去创造加入视觉内容的instruction-following数据。
为了将图像编码为视觉特征,以提示纯文本 GPT,我们使用了两类符号表示:
- 标题通常从不同角度描述视觉场景
- 边框通常定位场景中的物体,每个边框编码物体概念及其空间位置。如表1上部分
通过将图片用符号化的语言表示就可以将图像特征传递给纯文本的大语言模型中。

下面这一步是最关键的生成instruction-following data。
3. 通过上述的符号表示法将图像编码为LLM可识别序列,使用coco图像生成3种instruction-following data:表1下部
Conversation:我们设计了一段对话,对话内容是助理和一个就这张照片提问的人之间的对话。回答者的语气就像助手看到图片并回答问题一样。我们会就图片的视觉内容提出一系列不同的问题,包括物体类型、物体数量、物体动作、物体位置、物体之间的相对位置等。只有有明确答案的问题才会被考虑。如表10所示

Detailed description:为了对一幅图像进行丰富而全面的描述,我们创建了一个具有这种意图的问题列表。我们会提示 GPT-4,然后对该列表进行整理,详见附录中的表 9。对于每张图片,我们从列表中随机抽取一个问题,要求 GPT-4 生成详细描述。

Complex reasoning:上述两类问题主要针对视觉内容本身,在此基础上我们进一步创建深度推理问题。答案通常需要按照严密的逻辑进行逐步推理。
model
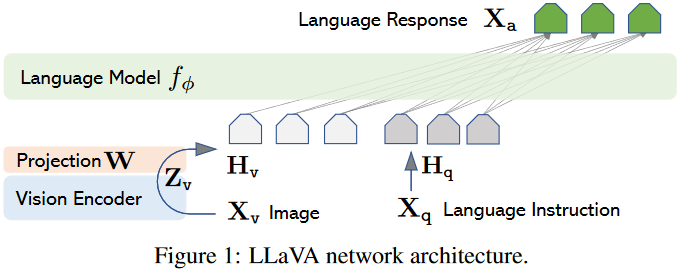
Language Model 选用LLAMA
对于输入图像 Xv,我们考虑使用预先训练好的 CLIP 视觉编码器 ViT-L/14 ,它能提供视觉特征 $Zv = g(Xv)$。我们在实验中考虑了最后一个变换器层之前和之后的网格特征。用简单的线性层将图像特征连接到词嵌入空间。具体来说,我们应用可训练的投影矩阵 W 将 Zv 转换为语言嵌入标记 Hq,其维度与语言模型中的单词嵌入空间相同。
$$
Hv=W*Zv, with Zv=g(Xv)
$$
本文使用了最简单的投影层,后续可能会考虑使用Qformer等架构。
训练
对于每个image $Xv$ ,本文生成多轮对话数据$(X_q^1,X_a^1,…,X_q^T,X_a^T)$ ,$T$ 是全部的轮次。将所有的answers作为助手的回应。
$$
X_{instruct^t = }\left{
\begin{aligned}
&\substack{\text{Random choose [$X_1^q,X_v$] or [$X_v,X_q^1$], the first turn t = 1} \ } \
&\substack{\text{$X^t_q$, the remaining turns t>1 } \ }
\end{aligned}
\right.
$$
这就形成了表 2 所示的多模态指令-跟读序列的统一格式。我们利用 LLM 最初的自动回归训练目标,对预测标记进行指令调整。

Table2 :用于训练模型的输入序列
$$
p(Xa|Xv,X{instruct})= \prod_{i=1}^{L} p_\theta(x_i; Xv,X{instruct},<i,Xa,<i)
$$
对于长度为 L 的序列,这里这个L的意思应该是L轮对话的意思,每一个x_i都是对应的一个答案。其中,θ 是可训练参数,$Xinstruct,<i$ 和 $Xa,<i $分别是当前预测标记 xi 之前所有回合中的指令和答案标记。我们明确添加了 Xv,以强调图像对所有答案都是有基础的这一事实。
一阶段特征对齐预训练

为了在概念覆盖率和训练效率之间取得平衡,我们将 CC3M 过滤为 595K 个图像-文本对。使用第 3 节中描述的天真扩展方法将这些对转换为指令跟随数据。每个样本都可视为一次单轮对话。为了构建 (2) 中的输入 Xinstruct,对于图像 Xv,随机抽取表 8 中的问题 Xq,该问题是要求助手简要描述图像的语言指令。预测答案 Xa 就是原始caption。在训练过程中,我们冻结视觉编码器和 LLM 权重,仅使用可训练参数 θ = W(投影矩阵)最大化 的可能性。这样,图像特征 Hv 就能与预先训练的 LLM 词嵌入对齐。这一阶段可以理解为为冻结的 LLM 训练一个兼容的视觉标记器。
二阶段端到端微调
我们只冻结视觉编码器的权重,并在 LLaVA 中继续更新投影层和 LLM 的预训练权重;即可训练参数为θ = {W, φ}投影层和LLM。我们考虑了两个具体的使用场景:
- 多模态聊天机器人。我们通过对第 3 节中收集的 158K 条独特的语言图像指令跟踪数据进行微调,开发了一个聊天机器人。在三种类型的回复中,conversation是多轮回复,而其他两种是单轮回复。它们在训练中统一采样。-
- 科学 QA。我们在 ScienceQA 基准上研究了我们的方法,这是第一个大规模多模态科学问题数据集,该数据集为答案注释了详细的讲座和解释。每个问题都有一个自然语言或图像形式的上下文。助手用自然语言提供推理过程,并从多个选项中选出答案。为了进行中的训练,我们将数据组织为单轮对话,问题和上下文为 $Xinstruct$,推理和答案为 Xa。
Experiments

LLaVA 根据问题和视觉输入图像预测答案。 GPT-4 根据问题、真实边界框和标题进行参考预测,标记教师模型的上限。在获得两个模型的响应后,我们将问题、视觉信息(以标题和边界框的格式)以及两个助手生成的响应提供给 GPT-4。 GPT-4 评估助理响应的有用性、相关性、准确性和详细程度,并给出 1 到 10 分的总体评分,其中评分越高表示整体表现越好。