BLIVA
Introduction
虽然现在的VLM已经通过并入视觉理解能力拓展了LLM在处理开放式的视觉问答的能力。然而这些模型不能准确地解释有文本注入的图像。
从图像中提取信息的标准过程通常涉及学习一组固定的查询嵌入。这些嵌入旨在封装图像上下文,并随后在LM中用作软提示输入。然而,这个过程仅限于标记计数,可能会限制对具有丰富文本上下文的场景的识别。
为了改进它们,本研究引入了 BLIVA:带有 Visual Assistant 的 InstructBLIP 的增强版本。 BLIVA 结合了来自 InstructBLIP 的查询嵌入,还直接将编码的补丁嵌入投影到 LLM 中。
现有的两种端到端的多模态大模型
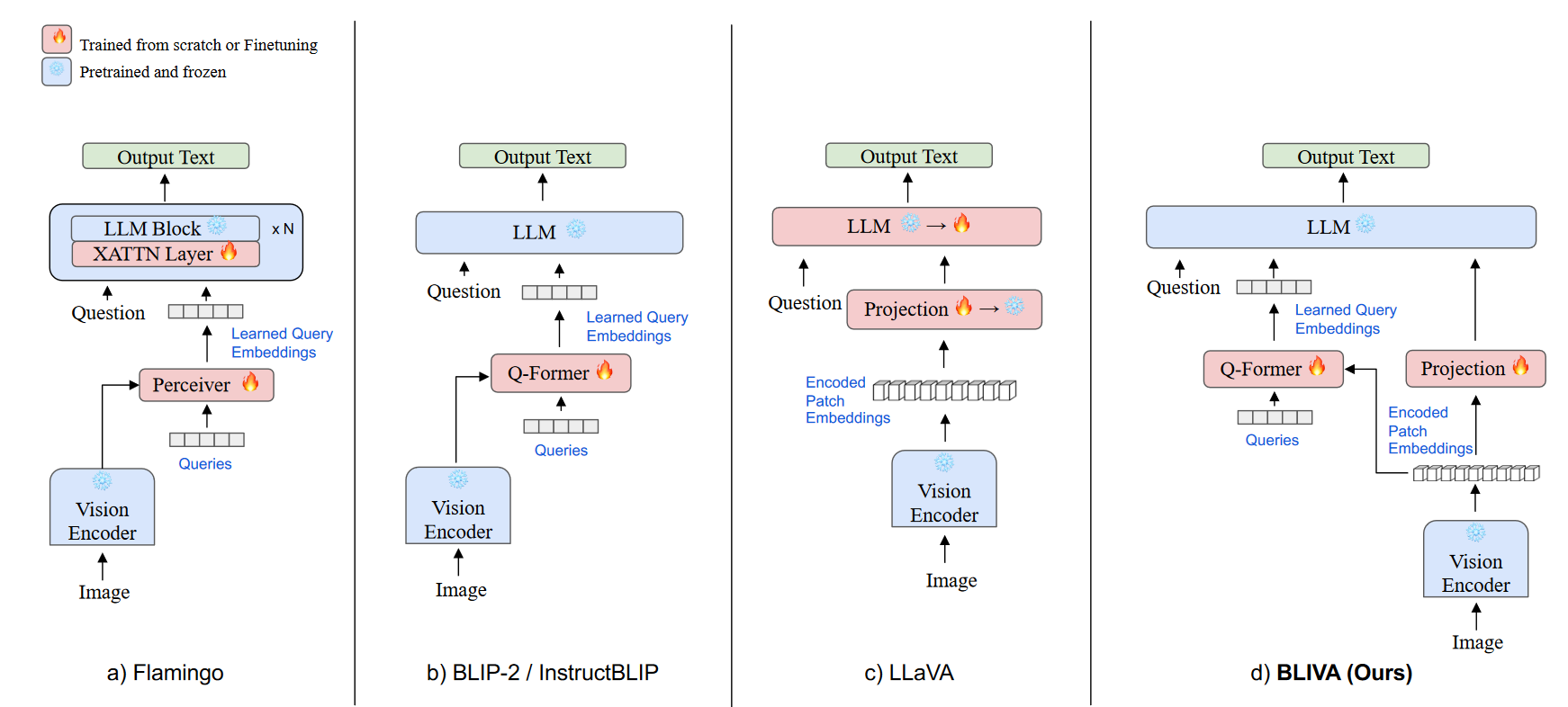
Figure 1:各种 VLM 方法的比较。 (a) Flamingo和 (b) BLIP-2 / InstructBLIP架构都使用一组固定的、小型的查询嵌入。这些用于压缩视觉信息以传输到法学硕士。相比之下,(c) LLaVA 将编码补丁嵌入直接与 LLM 对齐。 (d) BLIVA(我们的)通过将学习的查询嵌入与额外的编码补丁嵌入合并来建立在这些方法的基础上。
主要有两种类型的端到端多模式 LLM:
- 利用学习的查询嵌入进行 LLM 的模型。例如,MiniGPT-4 使用 BLIP2 中的冻结 Q-former 模块通过查询 CLIP 视觉编码器来提取图像特征。 Flamingo采用了 Perceiver Resampler,将图像特征减少到 LLM 的固定数量的视觉输出。
- 直接采用图像编码补丁嵌入的模型,例如 LLaVA,它使用 MLP 将其视觉编码器连接到 LLM。
然而,这些模型存在一定的局限性。一些模型采用 LLM 学习的查询嵌入,这有助于更好地理解视觉编码器,但可能会错过编码补丁嵌入中的关键信息。另一方面,一些模型通过线性投影层直接使用编码图像块嵌入,这可能在捕获 LLM 所需的所有信息方面能力有限。
model
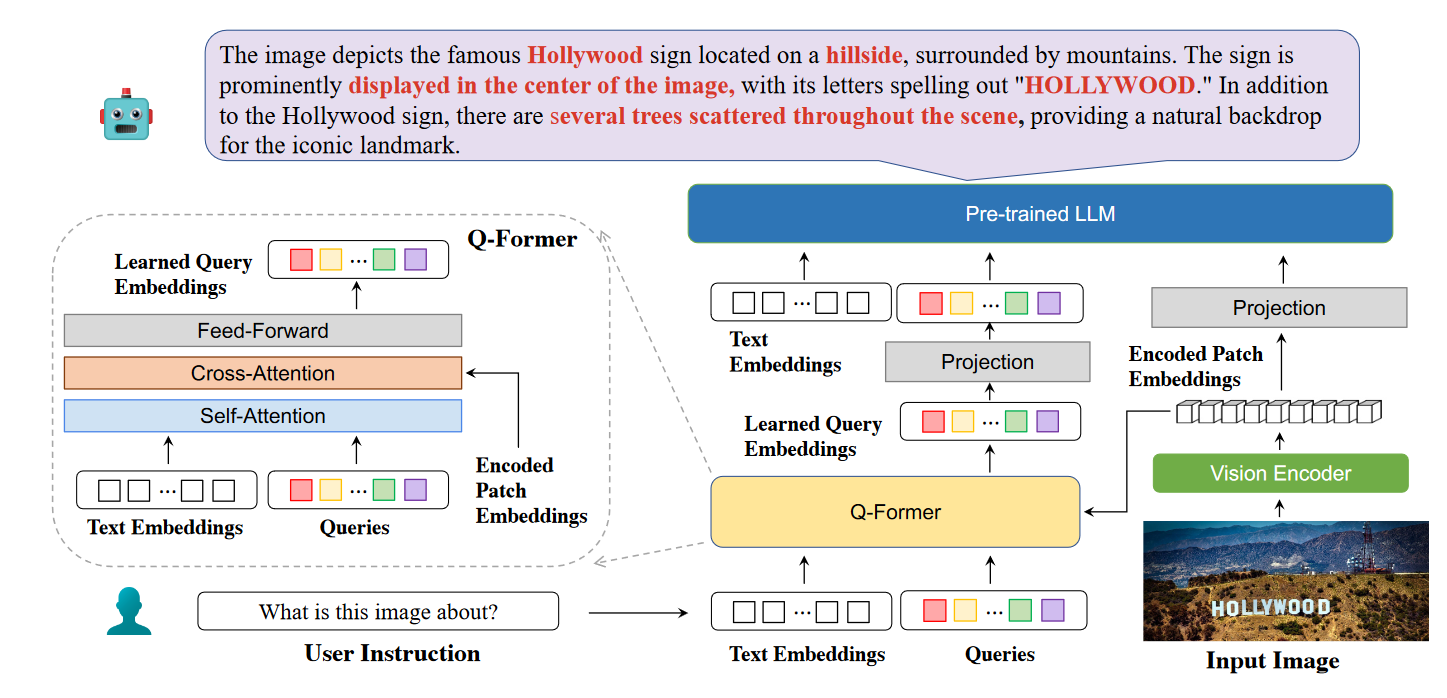
Figure 2: BLIVA 的模型架构。 BLIVA 使用 Q-Former 从冻结图像编码器生成的补丁嵌入中提取指令感知的视觉特征。然后,这些学习到的查询嵌入将作为软提示输入输入到冻结的语言学习模型(LLM)中。此外,系统通过完全连接的投影层重新利用最初编码的补丁嵌入,作为冻结的 LLM 视觉信息的补充来源。
- BLIVA:一个多模态 LLM 旨在合并与 LLM 更紧密结合的学习查询嵌入以及携带更丰富图像信息的图像编码补丁嵌入。
包含一个视觉塔(vision encoder)将输入图片的视觉特征编码成encoded patch embeddings。随后,其将被分别送到Q-former来提取精炼的学习到的查询嵌入,和投影层来允许LLM去学习富文本知识。我们将两种类型的嵌入连接起来并将它们直接提供给LLM。这些组合的视觉嵌入会立即附加在问题文本嵌入之后,作为LLM的最终输入。
细节
- visual encoder:ViT-G/14 from EVA-CLIP
- LLM:Vicuna-7B
Training
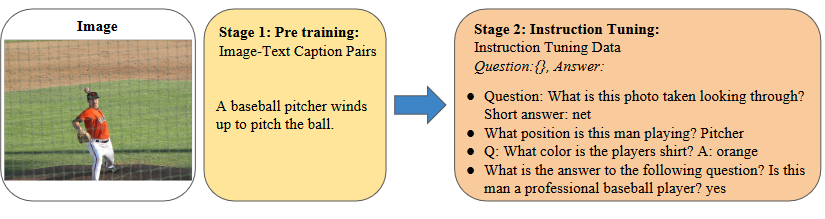
两步训练:
- 预训练阶段:目标是使用来自image captioning数据集中的图像文本对将LLM和视觉信息对齐。
- 预训练之后:经过预训练后,LLM熟悉视觉嵌入空间并可以生成图像描述。然而,它仍然缺乏辨别图像细节和回答人类问题的能力。在第二阶段,我们使用指令调整数据来提高性能,并进一步使视觉嵌入与LLM和人类价值观保持一致。
损失函数:LM loss
实验

Table 1: Zero-Shot OCR-Free Results on Text-Rich VQA benchmarks