X-LLM
Introduction
GPT-4展现了远超先前的视觉语言模型的多模态能力,但是其模型结构和训练方式依然未知。
因此本文提出X-LLM来将多模态数据通过X2L接口转换成外语再将他们传入LLM(ChatGLM)中。
X-LLM 使用 X2L 接口将多个冻结的单模态编码器和冻结的 LLM 对齐。
X2L接口由图像I2L接口、视频V2L接口和语音S2L接口组成,其中“X”表示多模态,“L”表示语言。
图像接口和视频接口具有相同的结构,我们采用BLIP-2中的Q-Former将视觉信息转换为外语表示。
视频接口将图像接口的参数与图像文本数据重用,但使用视频文本数据进行进一步训练,以使编码的视频特征与 LLM 保持一致。
语音接口利用连续集成触发(CIF)机制和变压器结构将语音表达转换为外语表示。
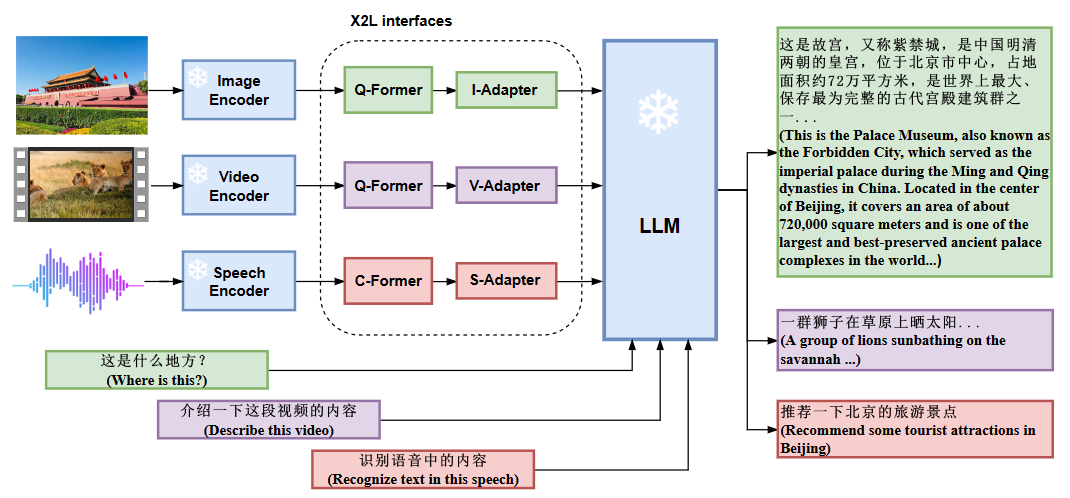
Figure 1
Model
对于视觉感知,我们采用ViT-g作为图像编码器和视频编码器。
对于语音感知,我们使用由卷积层和conformer 结构组成的语音编码器。
我们设计了一个将多模态信息与LLM对齐的模块,统称为X2L接口,包括图像接口、视频接口和语音接口。
图像接口和视频接口具有相同的结构,由Q-Formers和Adapter模块组成。
语音接口包括C-Former和Adapter模块。 C-Former 可以通过连续集成和激发(CIF)机制将来自语音编码器的帧级语音特征序列压缩为令牌级语音嵌入序列。由于令牌级语音嵌入序列与语音对应的转录的令牌序列严格对齐,因此使用令牌级语音嵌入表示语音可以有效减少将语音合并到 LLM 时的 GPU 内存使用量。
X2L Interfaces
- **The Image Interface :**图像接口由Q-Formers和I-Adapter模块组成。 Q-Formers 旨在将图像转换为语言,将从图像编码器获得的图像特征转换为具有 $L_i$ 准语言嵌入的序列。 I-Adapter 模块旨在对齐准语言嵌入的维度和 LLM 的嵌入维度。
- The Video Interface: 视频接口与图像接口结构相同,同样由Q-Formers和V-Adapter模块组成。我们使用均匀采样并用 T 帧表示每个视频。然后我们将每一帧视为图像。视频接口将每个帧特征转换为具有$L_i$准语言嵌入的序列。然后视频接口连接所有序列以获得最终的准语言嵌入,其长度为$T×L_i$。
- The Speech Interface : 语音接口由两部分组成,即C-Former和S-Adaptor。 C-Former是CIF模块和12层变压器结构的组合。
- 首先,CIF模块通过变长下采样将来自语音编码器的语音特征序列压缩为与相应转录长度相同的令牌级语音嵌入序列。假设语音编码器对输入语音发出的特征序列的长度为 U ,语音转录的令牌序列的长度为 $L_s$ ,则令牌级语音嵌入序列的长度应为 $L_s$ ( U 通常比 $L_s$ 长几倍)。
- 然后,变压器结构为来自 CIF 模块的标记级语音嵌入提供上下文建模。
- 最后,使用S-Adaptor将Transformer结构的输出投影到LLM的输入向量空间,进一步缩小语音和语言之间的语义差距。
Training
包含3个阶段:
转变多模态信息:训练每个 X2L 接口分别与其各自的单模态编码器对齐,以将多模态信息转换为语言。
将X2L表征与LLM对齐:单模态编码器通过X2L接口独立地与LLM对齐。
使用BLIP2第二阶段训练的Q-Former来初始化X-LLM中图像接口的Q-Former。为了使 Q-Former 适应中文 LLM,我们使用了一个组合数据集,总计约 1400 万个中文图像文本对进行训练。接下来,我们使用经过训练的图像接口来初始化视频接口(Q-Former 和 V-Adapter),并在翻译后的视频文本数据上训练视频接口。最后,我们使用 ASR 数据训练语音接口,以使语音接口的输出与 LLM 保持一致。应该注意的是,在整个第二个训练阶段,所有编码器和 LLM 都保持冻结状态,仅对接口进行训练。
整合多模态:所有单模态编码器都通过 X2L 接口与 LLM 对齐,以将多模态功能集成到 LLM 中。
在此阶段,我们使用构建的紧凑但高质量的数据来微调我们的模型。在微调过程中,我们使用以下模板中的预定义提示:
\n Answer: 在这个提示中,
代表从我们预定义的指令集中随机抽取的一条指令,包括“详细描述这张图片”、“你能描述一下你在视频中注意到什么吗”、“回答问题”等不同的形式。在基于图像的演讲中”。应该注意的是,我们不会专门针对这个特定的指令提示计算回归损失。因此,X-LLM可以集成多种模态,并根据需要根据各种指令组合生成更自然、更可靠的响应。