BERT
Introduction
BERT旨在通过联合调节所有层中的左右上下文来预训练未标记文本的深度双向表示。,这样BERT模型就可以只需一个额外的输出层就可进行微调。
先前手段:
feature-based
使用特定于任务的架构,其中包括预训练的表示作为附加功能。
fine-tuning
引入最少的特定于任务的参数,并通过简单地微调所有预训练参数来对下游任务进行训练。
针对fine-tuning:其中每个令牌只能关注 Transformer 的自注意力层中的先前令牌。这种限制对于句子级任务来说并不是最优的,并且当将基于微调的方法应用于标记级任务(例如问答)时可能非常有害,因为在这些任务中,从两个方向合并上下文至关重要。
BERT的解决方法:使用MLM进行预训练。
MLM
The masked language model随机屏蔽输入中的一些标记,目标是根据上下文预测屏蔽的原始词汇id。
模型
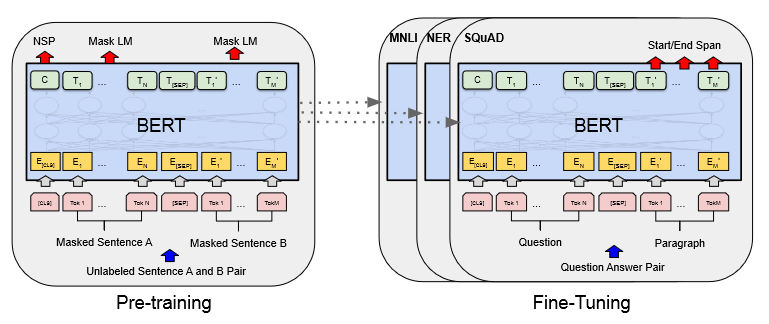
Figure 1:[CLS] 是添加在每个输入示例前面的特殊符号,[SEP] 是特殊的分隔符标记(例如分隔问题/答案)。
BERT的特点是它的预训练架构和最后的下游架构差距很小。
将层数(即 Transformer 块)表示为 L,隐藏大小表示为 H,自注意力头的数量表示为 A 我们主要报告两种模型大小的结果:$BERT_{BASE}$(L= 12,H=768,A=12,总参数=110M)和$BERT_{LARGE}$(L=24,H=1024,A=16,总参数=340M)。
使用WordPiece embedding,每个句子的第一个token总是一个特殊的分类标记([CLS])。与该标记对应的最终隐藏状态用作分类任务的聚合序列表示。
CLS
一句话理解:【CLS】就是一个向量,只是不是某一个字的向量,是一个够代表整个文本的的语义特征向量,取出来就可以直接用于分类了。
主要用于以下两种任务:
单文本分类任务:对于文本分类任务,BERT模型在文本前插入一个[CLS]符号,并将该符号对应的输出向量作为整篇文本的语义表示,用于文本分类,如下图所示。可以理解为:与文本中已有的其它字/词相比,这个无明显语义信息的符号会更“公平”地融合文本中各个字/词的语义信息。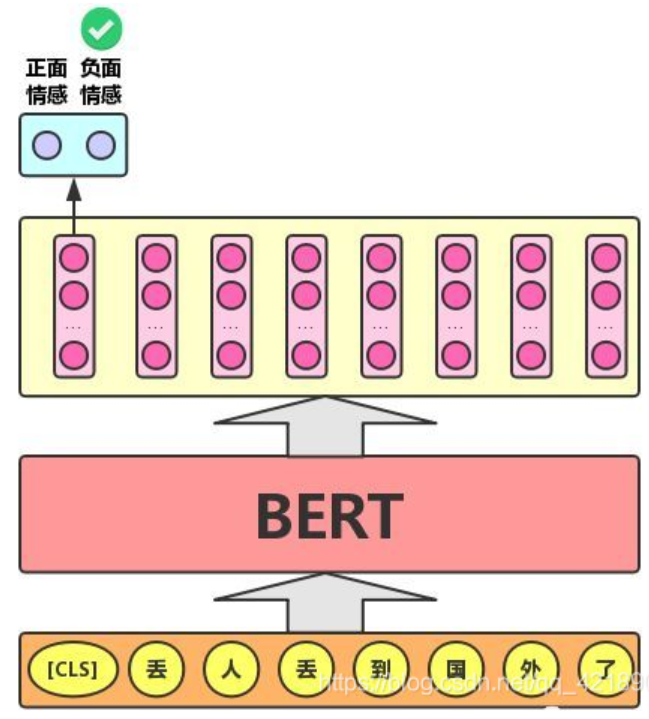
语句对分类任务:该任务的实际应用场景包括:问答(判断一个问题与一个答案是否匹配)、语句匹配(两句话是否表达同一个意思)等。对于该任务,BERT模型除了添加[CLS]符号并将对应的输出作为文本的语义表示,还对输入的两句话用一个[SEP]符号作分割,并分别对两句话附加两个不同的文本向量以作区分,如下图所示。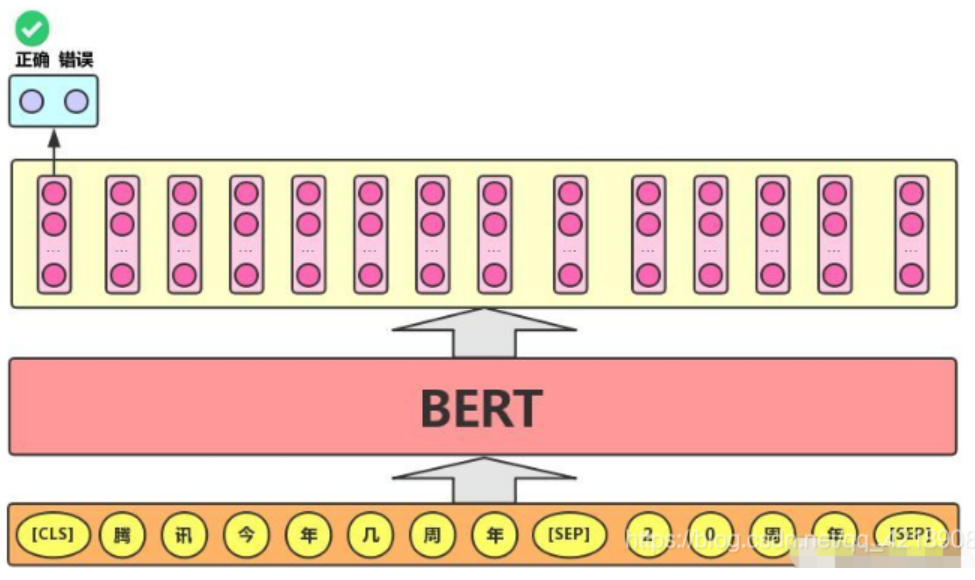
Training
two-steps:
pre-training:
在预训练期间,模型在不同的预训练任务中使用未标记的数据进行训练。
fine-tuning:
对于微调,BERT 模型首先使用预先训练的参数进行初始化,然后使用来自下游任务的标记数据对所有参数进行微调。每个下游任务都有单独的微调模型,即使它们是使用相同的预训练参数进行初始化的。
pre-training
预训练时使用两个无监督任务:
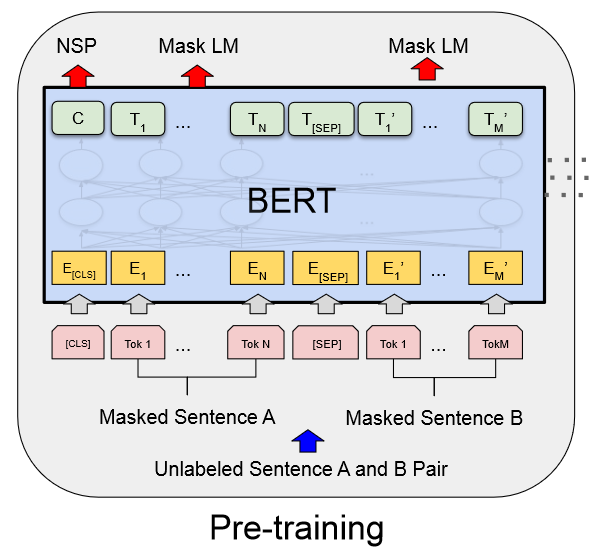
- Task 1:Masked LM
loss: cross entropy loss
训练数据生成器随机选择 15% 的 token 位置进行预测。如果选择第 i 个令牌,我们将第 i 个令牌替换为
(1) 80% 的时间为 [MASK] token (2) 10% 的时间为随机token (3) 10%的时间是未更改的第 i 个token。
然后,Ti 将用于通过交叉熵损失来预测原始令牌。
- Task 2: Next Sentence Prediction
为了训练理解句子关系的模型,我们预先训练二值化的下一个句子预测任务,该任务可以从任何单语语料库轻松生成。具体来说,当为每个预训练示例选择句子 A 和 B 时,50% 的时间 B 是 A 之后的实际下一个句子(标记为 IsNext),50% 的时间它是来自语料库的随机句子(标记为 IsNext)。作为NotNext)。C 用于下一句预测 (NSP)。
Pre-training data:
- BooksCorpus (800M words),
- English Wikipedia (2500M words)
fine-tuning
对于每个任务,我们只需将特定于任务的输入和输出插入 BERT 中,并端到端地微调所有参数。
在输入端,预训练中的句子 A 和句子 B 类似于
释义中的句子对,
蕴涵中的假设-前提对,
问答中的问题-段落对,以及
文本分类或序列标记中的简并文本-∅对。在输出处,令牌表示被馈送到令牌级任务的输出层,例如序列标记或问答,并且 [CLS] 表示被馈送到输出层以进行分类,例如蕴涵或情感分析。
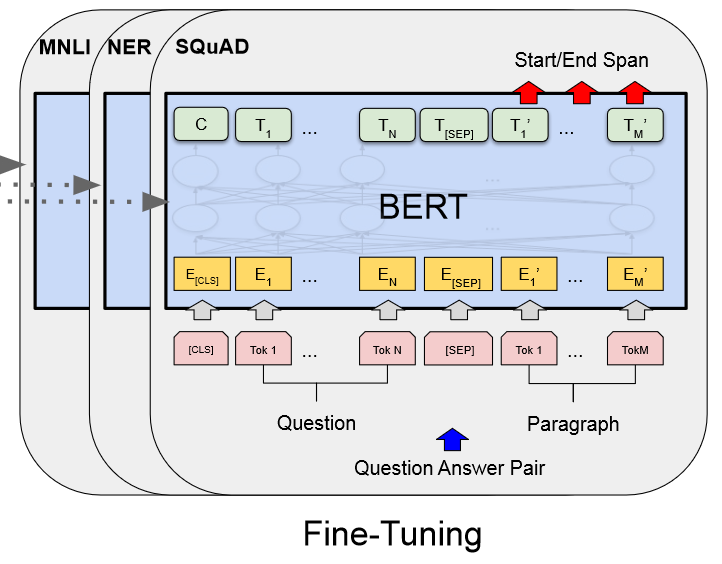
Input
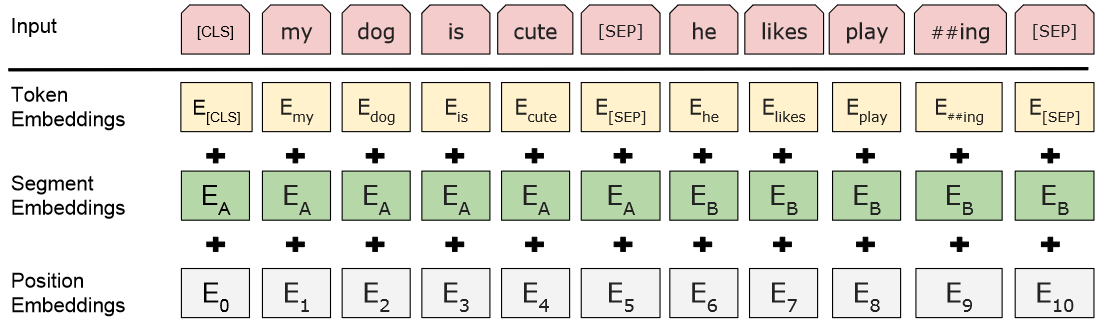
句子对被打包成一个序列。我们以两种方式区分句子。首先,我们用一个特殊的标记([SEP])将它们分开。其次,我们向每个标记添加一个学习嵌入,指示它属于句子 A 还是句子 B。如下图 所示,我们将输入嵌入表示为 E,将特殊 [CLS] 标记的最终隐藏向量表示为 C ∈ $R^H$ ,第 i 个输入标记的最终隐藏向量为 Ti ∈ $R^H$ 。
对于给定的标记,其输入表示是通过对相应的标记、段和位置嵌入求和来构造的。
实验
- GLUE
为了在 GLUE 上进行微调,我们如第 3 节中所述表示输入序列(对于单个句子或句子对),并使用与第一个输入标记([CLS])相对应的最终隐藏向量$ C \in R^H $作为聚合表示。微调过程中引入的唯一新参数是分类层权重 $ W \in R^{K×H}$ ,其中 K 是标签数量。我们用 C 和 W 计算标准分类损,即 log(softmax( $CW^T$ ))。
