Swin Transformer V2
Introduction
该论文目的是解决如下问题:
- 训练时的不稳定性。
- 如何有效将低像素预训练的模型迁移到更高的像素上。
提出的解决方式:
- 残差后归一化技术。
- 缩放余弦注意力方法可提高大视觉模型的稳定性。
- 对数间隔连续位置偏差技术。
Study on bias terms: 在 NLP 中,相对位置偏置法被证明是有益的,而不是原始 Transformer 中使用的绝对位置嵌入法。在计算机视觉中,相对位置偏置法更常用,这可能是因为视觉信号的空间关系在视觉建模中起着更重要的作用。常见的做法是直接学习偏置值作为模型权重。也有一些作品特别研究了如何设置和学习偏置项。
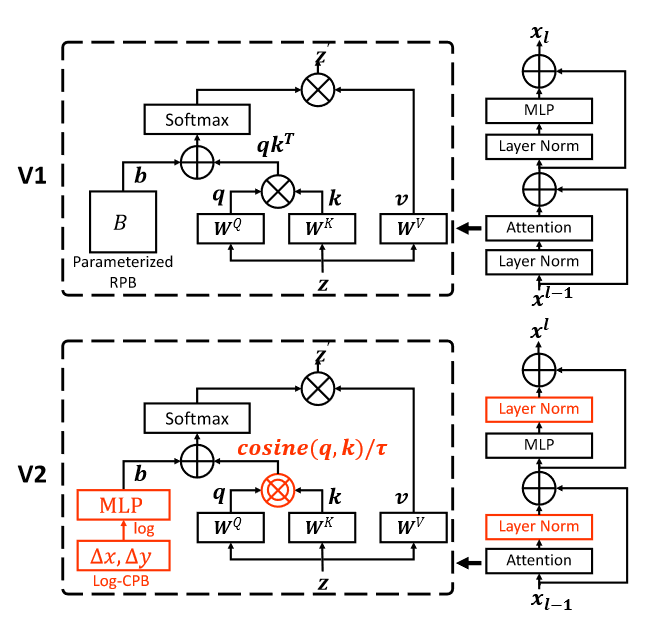
Figure 1:Swin Transformer V1与V2结构对比
模型
Relative position bias
$$
Attention(Q,K,V)=SoftMax(QK^T/ \sqrt{d} + B )V
$$
$B\in{R}^{M^2×M^2}$
$M^2$是一个window中patch的数量。
$Q,K,V\in{R^{M^2×d}}$ 是query,key和value。
d是隐藏层维度
在 Swin Transformer 中,沿每个轴的相对位置在 [−M + 1, M − 1] 范围内
相对位置偏差被参数化为偏差矩阵$\hat B∈R(2M−1)×(2M−1) $ B中元素取自$\hat B$
源码:
1 | #torch.arange默认的步长为1 |
经这个函数形成如下格式的4维矩阵
$$
R^{1×(2Wh-1)×(2Ww-1)×2}
$$
解析:
1 | import torch |
1 |
Continuous relative position bias
$$
B(\Delta x,\Delta y)=G(\Delta x,\Delta y)
$$
G是一个小型网络,中间使用ReLU激活的两层MLP。
元网络 G 为任意相对坐标生成偏差值,因此可以自然地转移到具有任意变化窗口大小的微调任务。在推论中,可以预先计算每个相对位置的偏差值并将其存储为模型参数,使得推论与原始参数化偏差方法相同。
Log-spaced coordinates
通过使用对数间隔坐标,当我们在窗口分辨率上传递相对位置偏差时,所需的外推率将比使用原始线性间隔坐标小得多。对于从预训练的 8 × 8 窗口大小转移到微调的 16 × 16 窗口大小的示例,使用原始原始坐标,输入坐标范围将从 [−7, 7]×[−7,7]至[−15, 15]×[−15, 15]。外推比为原始范围的 8/7 = 1.14倍。使用对数间隔坐标,输入范围将从 [−2.079, 2.079] × [−2.079, 2.079] 到 [−2.773, 2.773] × [−2.773, 2.773]。
这篇文章的外推比意思是值的大小差除以原始值:
$$
8=15-7\
Extrapolation Ratio = 8/7 \
\Delta = 2.773-2.079 = 0.684\
Extrapolation Ratio = \frac{0.684}{2.079} = 0.333
$$
- 源码
1 | if pretrained_window_size[0] > 0: |
- 公式
$$
\hat{\Delta x} = sign(x)*log(1+|{\Delta x}|),\
\hat{\Delta y} = sign(y)*log(1+|{\Delta y}|)
$$
Scaled cosine attention
原始的自注意力计算,相似的像素对是使用点积来计算query和key向量的。当这种方法被用到大的视觉模型上时一些块和头的学习注意力图经常由几个像素对主导,特别是在 res-post-norm 配置中。
$$
Sim(q_i,k_j)=\cos(q_i,k_i)/τ +B_{ij}
$$
$\tau$ 是一个可学习参数
经过查阅源码发现其本质就是在点积前进行归一化保证最后进行点积的向量的长度是单位长度,最后出来的点积结果就是两向量间的角度。
- 源码:
1 | attn = (F.normalize(q, dim=-1) @ F.normalize(k, dim=-1).transpose(-2, -1)) |
- 解析
attn = (F.normalize(q, dim=-1) @ F.normalize(k, dim=-1).transpose(-2, -1))
这行代码计算了查询(q)和键(k)之间的注意力得分。首先,通过F.normalize函数对查询和键进行归一化,使它们具有单位长度。然后,使用矩阵乘法@计算查询和键的内积,得到注意力得分矩阵attn。这个矩阵描述了查询与每个键的相关性或相似度。logit_scale = torch.clamp(self.logit_scale, max=torch.log(torch.tensor(1. / 0.01))).exp()
这行代码通过对self.logit_scale进行限制和指数化,得到一个用于缩放注意力得分的比例因子。self.logit_scale可能是一个模型参数,通过对其进行限制,确保缩放因子不会过大。torch.clamp函数用于限制self.logit_scale的最大值为torch.log(torch.tensor(1. / 0.01)),然后使用exp()函数进行指数化。attn = attn * logit_scale
这行代码将注意力得分矩阵attn与缩放因子logit_scale相乘,对注意力得分进行缩放。这个缩放操作可以调整注意力权重的范围和重要性,以适应模型的需要。
后置归一化
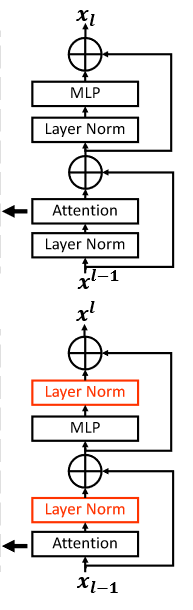
- 原先问题
如上图所示,原先的前置归一化手段会使得每次合并后幅度被积累(因为先进行归一化再进行Attention的,也就是Attention这一步可能会将输出值变得幅度很大(因为有投影))
- 改进后
在这种方法中,每个残差块的输出在合并回主分支之前被归一化,并且当层更深时主分支的幅度不会累积。