Visual Tasks via Soft Token
introduction
关于通用计算机视觉模型的现有相关研究大多集中于统一架构和预训练。少数研究旨在为多种视觉任务开发一种模型,但它们通常只适用于有限的任务。在本文中,我们的目标是为各种视觉任务提供真正通用的求解器。为此,我们首先注意到一个被忽视和未充分探索的关键障碍:语言任务的输入和输出由相同形式的语言标记表示,而不同计算机视觉任务的输出形式则更加多样化。例如,物体检测的输出是一组坐标和标签;语义分割的输出是一个离散标签图;深度估计的输出是一个带有浮点数值的图像;而流量估计的输出则是一个向量场。
本文通过一个通用标记化器将各种视觉任务的输出空间统一编码为一组标记,从而解决了这一障碍。
模型结构
框架由三部分组成:
- tokenizer(标记化器)
- detokenizer (解标记化器)
- task solver (任务求解器)
- tokenizer和detokenizer由VQ-VAE实例化,任务求解器由auto-regressive encoderdecoder model(自回归编码器解码器模型)实例化。
- 在训练过程中,任务注释首先由标记化器映射为离散标记,并用作训练任务求解器的监督。在推理过程中,任务求解器预测的标记由解码器解码为任务输出。
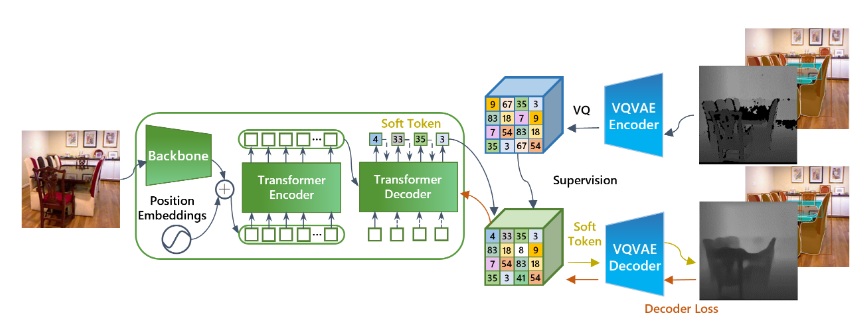
模型内部结构
- Task-solver:
- encoder是一个Swin Transformer,有6个标准transformer块,每个块包含一个自注意和一个FNN。
- decoder包含6个块,每个块包含一个自注意力,一个FNN,一个交互注意力。
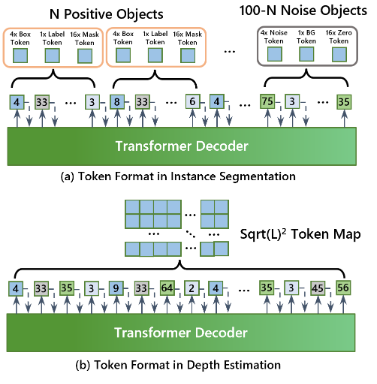
创新
软标记由概率矢量表示,矢量中的每个值都表示属于编码本的概率。当一个软标记被输入到解码器的输入端或下一个标记预测网络的输入端时,其输入嵌入是由基于概率值的编码本嵌入的加权平均值计算得出的。软标记方法将标记空间视为连续空间,而不是原来的离散空间,从而扩大了 VQ-VAE 的使用范围。
提出了一种掩码增强技术,用于处理注释中存在损坏、未定义或无效值的视觉任务。深度估计就是此类任务的一个典型例子,其中的遮挡区域没有定义。未定义的区域会给 VQ-VAE 标记化器和去标记化器的训练带来困难,因为它不知道在未定义的区域应该重建什么。为了解决这个问题,我们在训练 VQ-VAE 时随机屏蔽了输入深度图中的几个斑块。与未定义区域不同的是,手动屏蔽的补丁具有地面实况注释,这有助于训练 VQ-VAE 网络,使其能够恢复未定义区域的地面实况。在实验中,我们发现这项技术显著提高了深度估计的准确性。掩码增强技术还可用于其他具有类似未定义或损坏注释的视觉问题,因此增强了我们的统一任务求解器的通用性。

软标记
在典型的自动回归预测程序中,==具有最大预测概率的标记被选为输出,并将其嵌入作为下一步预测的解码器输入。这种方法被称为硬推理。==然而,由于通过 VQ-VAE学习的不同标记之间并非完全独立,标记之间的相关性可能会影响标记预测的准确性,从而使硬推理可能无法达到最佳效果。==为了充分利用相关性,推理中采用了软标记技术:软标记不是直接使用单个标记的嵌入,而是将不同标记的嵌入按其预测概率加权平均。==除了应用于任务求解器以更准确地预测下一个标记外,同样的想法也可用于解标记器以获得更好的重构结果。
掩码增强
深度估计数据集中的地面真实深度图通常会有一些未标注深度信息的损坏区域。在传统的深度估计框架中,这些区域会在训练过程中被忽略。我们面临两个挑战:首先,虽然我们在训练 VQ-VAE 时也忽略了这些区域,但重建后的区域仍然不正常(见图 3),进一步影响了任务求解器的训练,使最终结果也有很多伪像;其次,VQ-VAE 预测的标记对应于 322 个补丁,其中可能包含正常像素和损坏像素。因此,忽略标记很难解决这个问题。

- 我们在 VQ-VAE 的训练中引入了掩码增强技术来缓解这一难题。具体来说,我们在输入的深度图像中随机屏蔽一些区域,然后使用其原始深度信息作为监督。这样,VQ-VAE 就能以合理的结果完成/恢复一些损坏的区域。