ViLT
现有研究
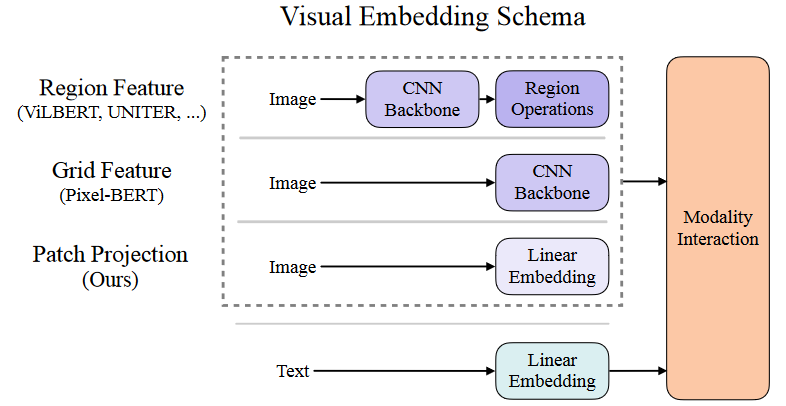
目前的 视觉语言预训练(VLP )方法==严重依赖于图像特征提取过程==,其中大部分涉及区域监督(如物体检测)和卷积架构(如 ResNet)。
上图中第一列就是引入CNN和目标识别的网络,第二列只使用CNN Backbone提取特征图再使用一个线性层将特征图处理一下即可。
引入区域性特征提取的原因:transformer无法接受图片这么长的序列,需要将图片处理成可以被接受的序列长度,类似文本的token,再将这些==离散的特征==进行自监督学习。
这样的区域性特征带来了如下问题:
- 运行速度慢,需要把图片先过一遍目标检测。
- 特征分类少,现有的分类模型最多也就几千类,coco只有80类,这样势必无法充分满足对于图片提取的需求。

根据上图可以看出来,使用目标检测的网络效果是最优的,而第二列使用像素分割的方式明显效果大大下降。
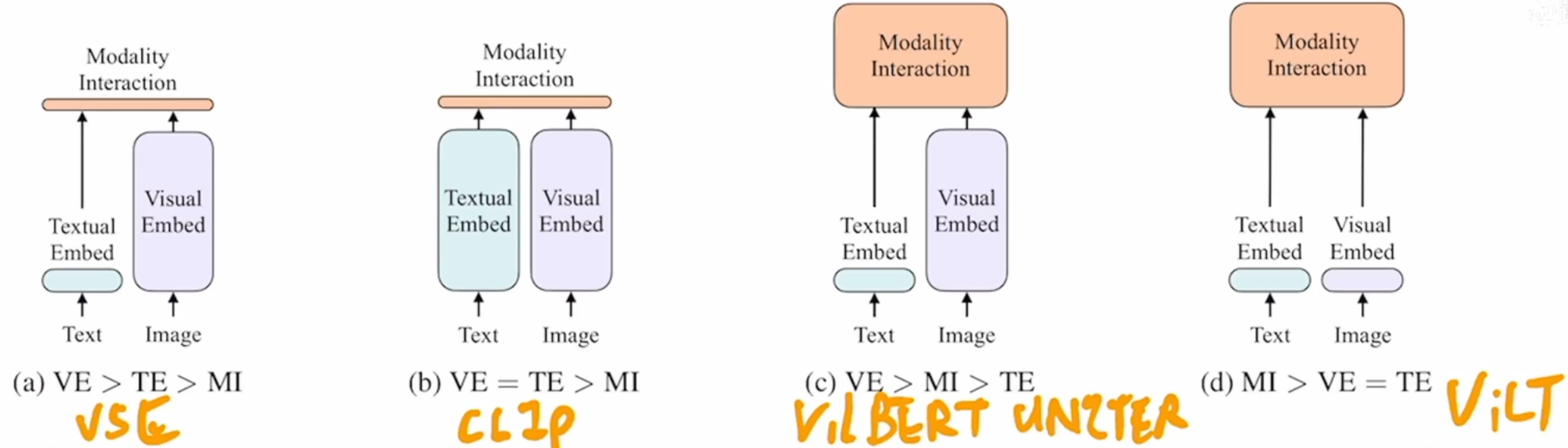
从左到右依次是目前不同类型VLP模型的结构图,==应该加大模态融合层==的存在才能提高效果。
简单模态交互都无法有效完成NLVR2的任务。即使是来自表现优异的单模态嵌入器(CLIP)的简单融合输出,也可能不足以学习复杂的视觉和语言任务,这就更需要一种更严格的跨模态交互方案。
本文做法
不使用卷积或者区域特征
- 委托转换器模块来提取和处理视觉特征,而不是单独的深度视觉嵌入器。这种设计从本质上大大提高了运行时间和参数效率。
- 首次通过实证研究表明,VLP 训练方案中前所未有的==全词屏蔽和图像增强技术==进一步推动了下游性能的提高。
模型结构
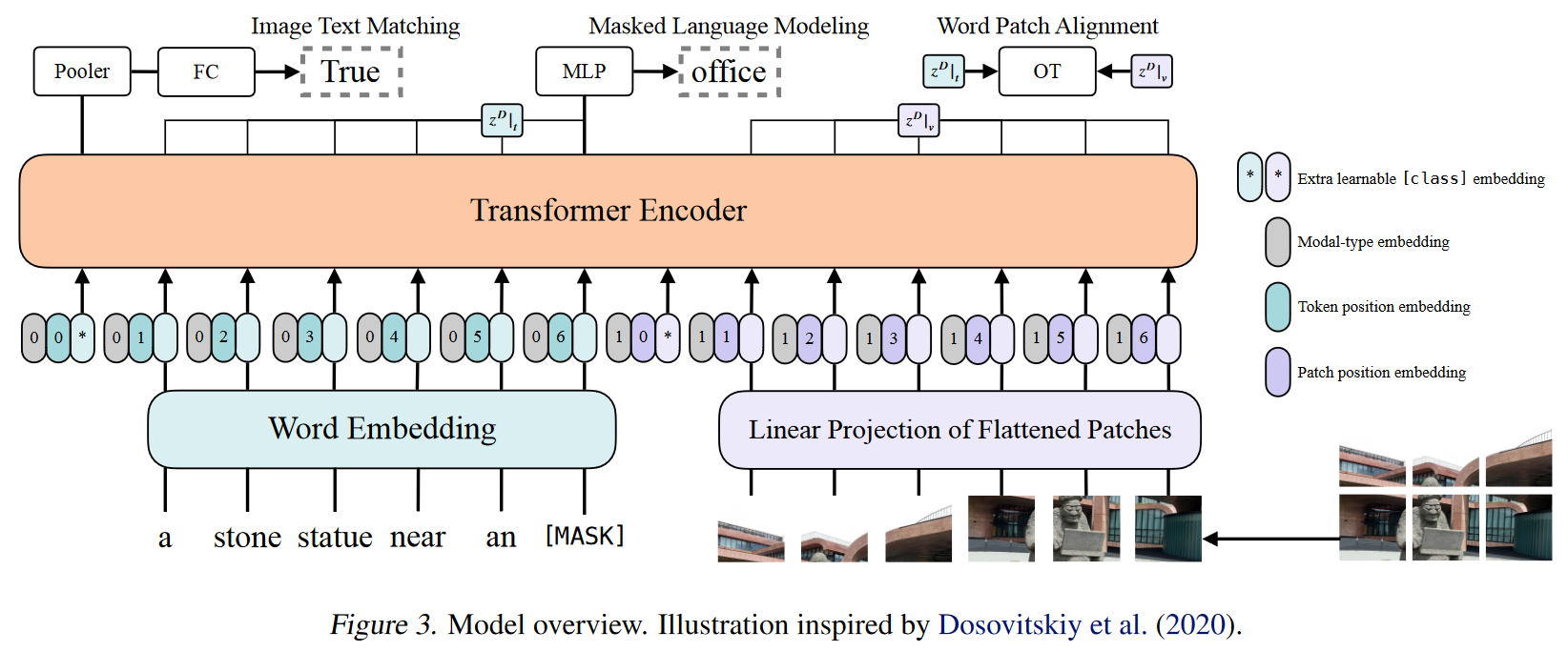
对图像补丁进行线性投影。补丁投影嵌入由ViT引入。
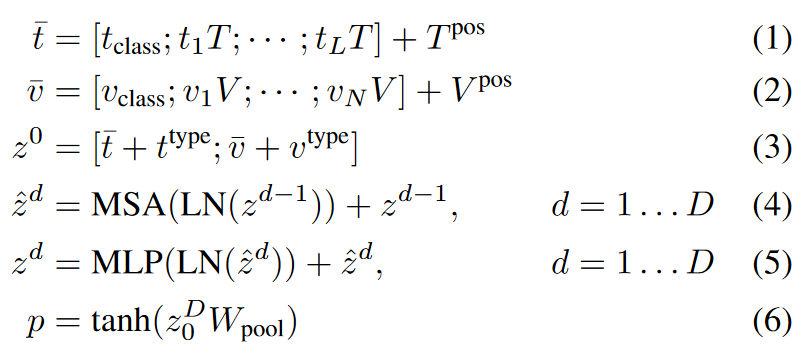
文本 t ∈ R^L×|V|^ 以单词嵌入矩阵 T∈ R^|V|×H^ 和位置嵌入矩阵 T^pos^∈ R^(L+1)×H^ 嵌入到 ̄ t∈ R^L×H^ 中。
输入图像 I ∈ R^C×H×W^ 被切片为图块并展平为 v ∈ R^N×(P^^2^^·C)^,其中 (P, P ) 是图块分辨率,N = HW/P 2。随后是线性投影 V ∈ R^(P2·C)×H^ 和位置嵌入 V pos ∈ R^(N+1)×H^ ,v 嵌入到 ̄ v ∈ R^N×H^ 中。
文本和图像嵌入与其相应的模态类型嵌入向量 t^type^, v^type^ ∈ R^H^ 相加,然后连接成组合序列 z0。上下文向量 z 通过 D (transformer layer)深度变换层迭代更新,直到最终的上下文序列 z^D^。 p 是整个多模态输入的池化表示,通过对序列 z^D^ 的第一个索引应用线性投影 Wpool ∈ R^H×H^ 和双曲正切来获得。
创新
全词屏蔽:
为了充分利用来自其他模态的信息,全字掩码对于 VLP 特别重要。例如,使用预先训练的 bert-base-uncased 分词器将单词“giraffe”分词为三个单词标记 [“gi”、“##raf”、“##fe”]。==如果并非所有标记都被屏蔽,例如 [“gi”、“[MASK]”、“##fe”],则模型可能仅依赖于附近的两个语言标记 [“gi”、“##fe”] 来预测屏蔽的“##raf”,而不是使用图像中的信息==。
图像增强
应用==RandAugment==。我们使用了除以下两个方法之外的所有方法:
- 颜色反转,因为文本通常也包含颜色信息。
- 剪切,因为它可能清除分散在整个图像中的小但重要的对象。我们使用 N = 2、M = 9 作为超参数。我们将在第 4.5 节和第 5 节中讨论其影响。
训练
优化器: AdamW
learning rate=10^-4^
weight decay=10^-2^
实验
Classification Tasks
视觉问题解答。VQAv2 任务要求用自然语言给出图像和问题对的答案。注释的答案原本是自由形式的自然语言,但通常的做法是将该任务转换为具有 3129 个答案类别的分类任务。按照这种做法,我们在 VQAv2 训练集和验证集上对 ViLT-B/32 进行了微调,同时为内部验证保留了 1,000 张验证图片及其相关问题。
自然语言视觉推理。NLVR2 任务是一项二元分类任务,由两幅图像和一个自然语言问题组成。由于与预训练设置不同,有两幅输入图像,我们采用了配对法。在这里,==三连输入被重新组合为两对(问题、图像 1)和(问题、图像 2)==,每对都要经过 ViLT。头部将两个池化表示的连接(p)作为输入,并输出二进制预测结果。