VLMo
模型架构
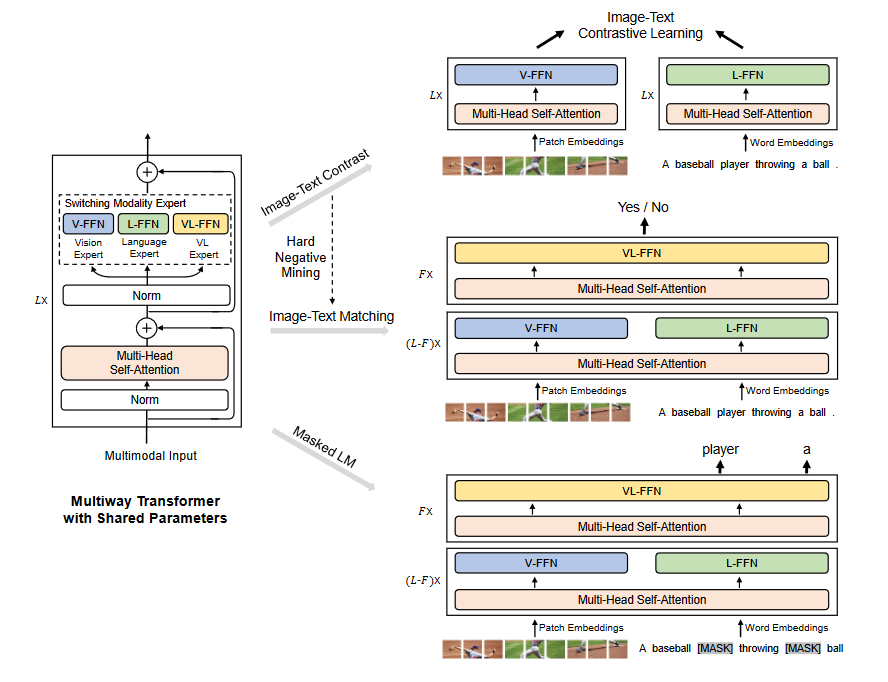
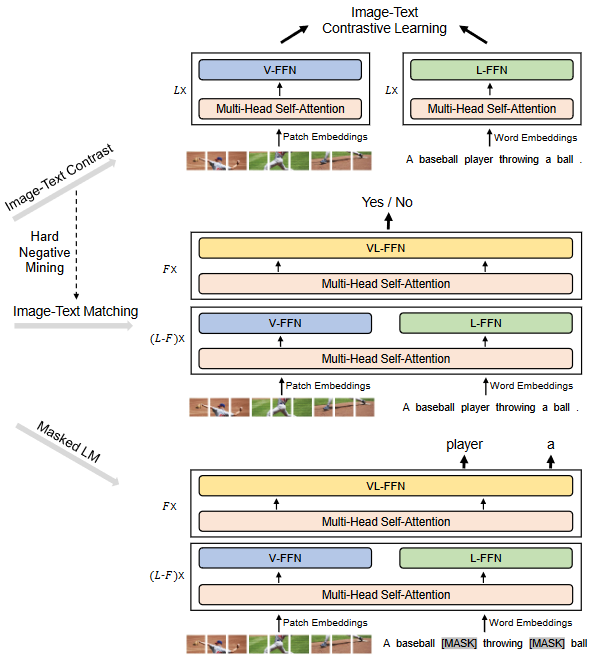
- Multiway Transformer结构包含3个模态专家:
- V-FFN专门用于处理图像编码。
- L-FFN专门用于处理文本编码。
- VL-FFN专门用于处理图像文本对编码。
- 权重共享
模型输入
图像部分
图像的输入是采用像素块这样的结构。一张2D图像的大小为(H,W,C),(H,W)为图像的输入分辨率,C是通道数。
假如一个像素块的大小是(P,P),一张图片可以塞下N=HW/P^2^个像素块,图像又有C个通道也就是最后会有N个像素块,每个像素块的分辨率为P^2^C,将其表示为一个N X(P^2^C),然后将图像补丁平铺成矢量,并进行线性投影,以获得补丁嵌入。最后加入一个[cls]标记,可学习的一维位置嵌入,和图像类型嵌入。
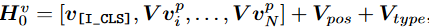
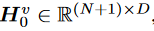
文本部分
遵循BERT,通过WordPiece 将文本标记为子词单元。序列开始标记([T_CLS])和特殊边界标记([T_SEP])被添加到文本序列中。文本输入表示 Hw 0 =
R(M+2)×D通过对相应的单词嵌入、文本位置嵌入和文本类型嵌入求和来计算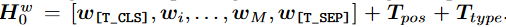
M表示标记化子字单元的长度。
文本图像表示
(H
0)^vl^=[(H0)^w^,(H0)^v^]
模型训练
分阶段训练
目的是为了更高效的利用更多数据(纯图像,纯文本),而不仅仅利用图像-文本对。可以学习到更具通用性表征。

- 第一阶段
- ==使用BEiT中提过的遮蔽图像建模技术对V-FFN进行训练。==
- 之后使用遮蔽文本(BERT)技术对L-FFN进行训练。
- 第二阶段
- 用预训练好的视觉和文本网络来初始化文本-图像的预训练。训练时使用的3个loss函数与ALBEF相同。
亮点
- 在预训练环节,作者首先==在图像数据上对attention结构进行了训练,而在文本数据上却直接选择将attention层冻住==,甚至不进行微调。但效果依然及其出色,作者在文中也做了实验,发现如果先==在文本数据上训练在图像训练时将attention冻住效果就会变得很差。==这个现象或许可以为后续的工作进行极大的训练时间和资源的减轻。
- 这篇文章作者提出的共享权重确实亮眼,相较于双塔结构,这更像是单塔结构,参数量大大下降,效果却也很好。