TART
模型结构
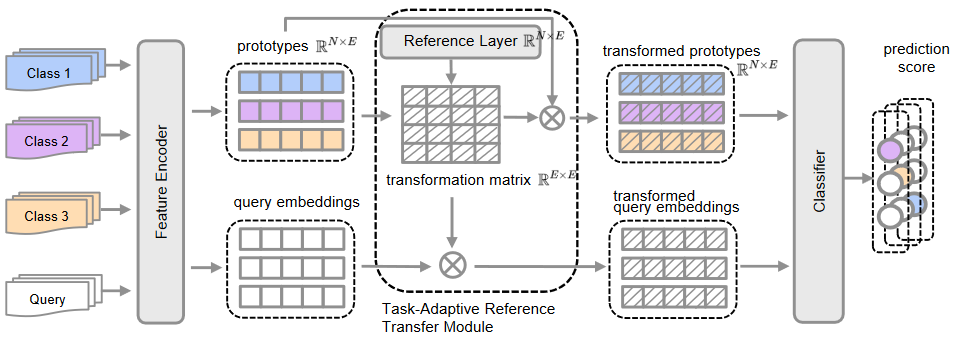
网络的核心做法即目的
- 通过将每类原型转换到任务自适应度量空间的固定参考点上来提高泛化能力。
分类任务现状
- 对应那些在单个特征空间独立表现每个特征的方法,他们的表现很大程度上==取决于类间方差==,他们处理在少样本学习的过拟合问题通过直接采用支持样本的隐藏特征作为分类器。但是==当类间的区别过小就会出现分类失败的情况==。(如图中Task1,很难分辨Science和Tech这两个类)

- 但是将分类任务中的Tech换成Taste就可以发现分类的准确性大大提高。(如上图Task2)
解决方法
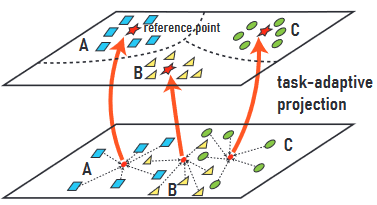
- 对于在原始特征空间中无法区分的可比类别,如果==我们能将它们的类别原型投影到另一个小空间中的每个类别的固定点(称为参考点)上==,则有助于增强转换空间中类别原型之间的发散性。
- 提出了一种==新的判别参考正则化方法,以最大限度地提高任务适应性度量空间中变换原型之间的发散性==,从而进一步提高性能。
网络构成
- Task-Adaptive Reference Transfer Module(任务自适应参考转移模块) :用于构建一个任务自适应度量空间,并将上下文嵌入从任务无关空间投射到任务特定空间。
- Discriminative Reference Regularization (判别参考正则化):用于测量转换原型之间的距离。
方式
- 首先,我们引入一组参考向量 {r1, .rN } 作为变换空间的固定点,通过线性层(reference layer称为参考层)学习。我们使用参考层的权重矩阵和支持上下文嵌入的原型集来计算变换矩阵。形式上,==让 R 表示参考层的权重矩阵,P 表示支持文本的原型矩阵。我们通过找到 P W = R 的矩阵来构建转换矩阵 W。==
- 每一类原型可通过==平均情景嵌入==得到。(如下)
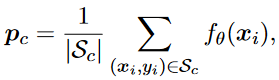
- S
c代表c类样本。- 参考权重矩阵被定义为
,R ∈ R^N×E^。其中R的每一行都是在==训练阶段学到的==参考向量。
- 对于每一个查询输入,给定一个距离函数d可以用d结合softmax函数作为每一个查询与原型的概率来区分。
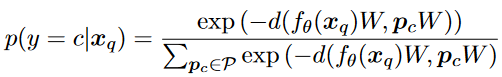
- x
q是查询输入。- p
c是原型向量。
LOSS函数
- 距离函数:通常使用==余弦距离或欧氏平方距离==,通过最小化分类损失L
cls来最小化距离。
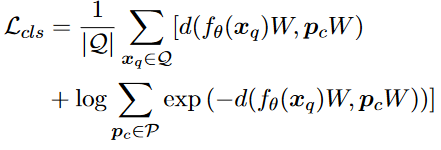
- 针对这个函数,x
q和pc是一对对应向量,损失函数实际就是CrossEntropy。- 前面的概率实际代表在输入为x
p的情况下,对应标签为c的概率。- 由于标签类是一个长度为c的one-hot向量除了c之外的标签为0,所以根据CrossEntropy算法,实际结果只有对应标签的概率,加一个log就成中括号里的部分,前面的求和实际是对所有的输入进行考虑。
- 参考向量的训练:P = {p1, . . . , pN }是原型集,W是转换矩阵。通过下面的损失函数即可最大化参考层。
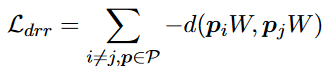
总loss函数:L = Lcls + λLdrr
- 本文设置λ为0.5。
算法

- ==模型参数和参考层是随机初始化的==。
- 给定每个训练集,我们从训练数据集中随机选择支持集和查询集中的 T 个集。
- 每个集由 N 个类别中的 K 个标记样本组成。
- 利用类别 c 的支持集 S
c,得到每个类别的原型 pc(第 5 行)。 - 转换矩阵 W 是作为任务适应性投影矩阵计算的(第 7-9 行)。
- 对于每个查询输入,转换后的查询嵌入和每个转换后的原型之间的距离都是在任务适应性度量空间中测量的,并利用这些距离计算分类损失 Lcls(第 10-12 行)。
- 判别损失是通过每一集的原型集获得的(第 15 行)。根
- 据总损失 L 更新特征编码器和参考层的可学习参数(第 16 行)。这一过程在每一集剩余的新文本和新查询中重复进行。
总结
实际上第一轮就是用随机初始的参考层,和提取的原型来计算W,再用W去算loss最后==每一轮更新一下初始层(不更新W,W是算出来的)==。