Blip
模型架构
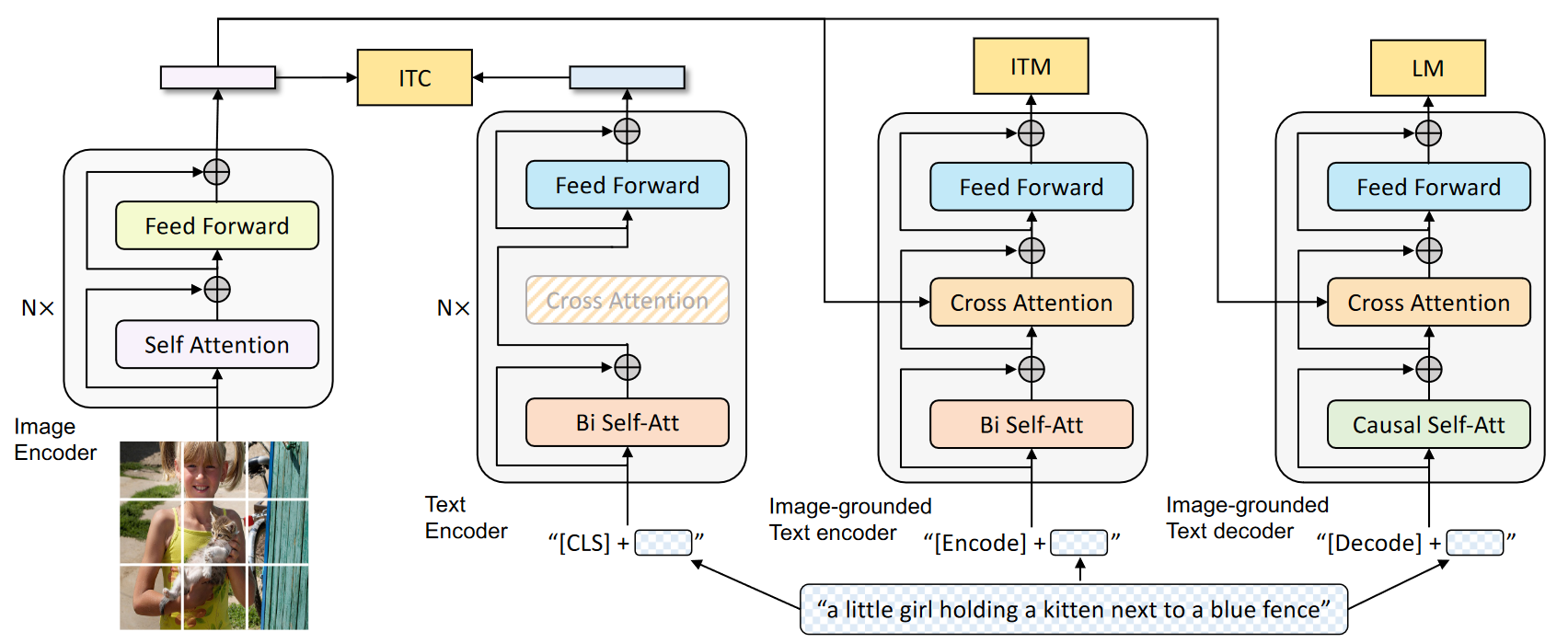
3种模块
- 单模态编码器,在上图中就表现为左侧的两个模型,就是SA和FF。
- 基于图像的文本编码器,对应上图第三个,在单模态基础上多加了一个CS。
- 基于图像的文本解码器,结构与基于图像的文本编码器类似,就是SA带有mask变成解码器,用来完成文本生成任务。
模型训练
- 由于本次任务是做文本生成,因此完全使用encoder结构肯定就不行,需要引入decoder结构。
- 使用vision transformer将图像编码并使用[CLS]token来表示全局图像特征。
- ==文本编码器与 BERT==相同,在文本输入的开头附加一个 [CLS] 标记,以概括句子内容。
- Image-grounded text encoder:一个特殊[Encode]标记被附加在文本中,[Encode] 的输出嵌入被用于作为图像-文本对的多模态表示。
- Image-grounded text decoder:[Decode]标记被用于表示序列的开始。用因果自注意层取代了图像基础文本编码器中的双向自注意层
输入
- 图像:将输入图像划分为多个片段,并将其编码为嵌入序列,再加上一个 [CLS] 标记来表示全局图像特征。
loss
每个图像-文本对只需通过一次计算量较大的视觉转换器,以及通过三次文本转换器,其中不同的功能将被激活,以计算三种损失。
3种loss:
- ITC
- ITM
- ==LM(这里与ALBEF和VLMo不同)==:文本编码器和文本解码器共享除 SA 层以外的所有参数,嵌入层、CA 层和 FFN 在编码和解码任务之间的功能类似,因此共享这些层可以提高训练效率。
Filter Captioner

由于注释成本过高,高质量的人工注释图像文本数量有限。而从网上自动下载的图像文本对中的文本又很难准确的描述的图像
引入Filter 和 Captioner的目的是:从带有噪声的图像-文本对中学习。
两部分
Captioner:为网络图片生成标题。是一种Image-grounded text decoder。给定图像生成文本用LM目标来微调。
- 使用LM作为目标进行微调,来解码给定图像的文本,每张图片生成一个标题。
Filter去除噪声图片-文本对。是一种Image-grounded text encoder。
- 使用ITC和ITM目标进行微调来学习文本和图像是否吻合。
image transformer使用ViT-B,Text transformer使用BERT
base
效果
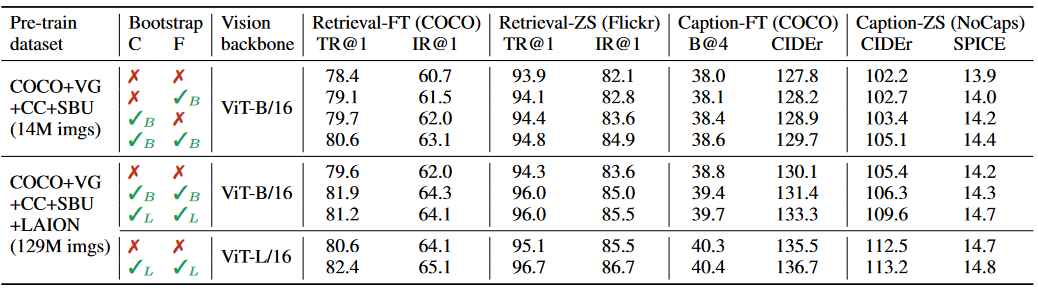
- 该表展示了在Captioner和Filter在不同预训练数据集以及不同下游任务上的表现,可以看出当单独使用Captioner或Filter时效果都有上升,同时使用效果更好。
- TR代表text retrieval,IR代表image retrieval。B/L是ViT-B和ViT-L。

- 该表展示了不同共享方式下在下游任务上的表现,可以发现当共享除了self attention层以外的其他全部层时效果变好。(对于encoder和decoder)
训练方式
*
数据集
- coco
- LAION
- Visual Genome
- Conceptual Captions
- Conceptual 12M
- SBU captions
亮点
- 使用了VLMo中的共享参数机制。
- 结合了ALBEF和VLMo