AlBEF
模型架构
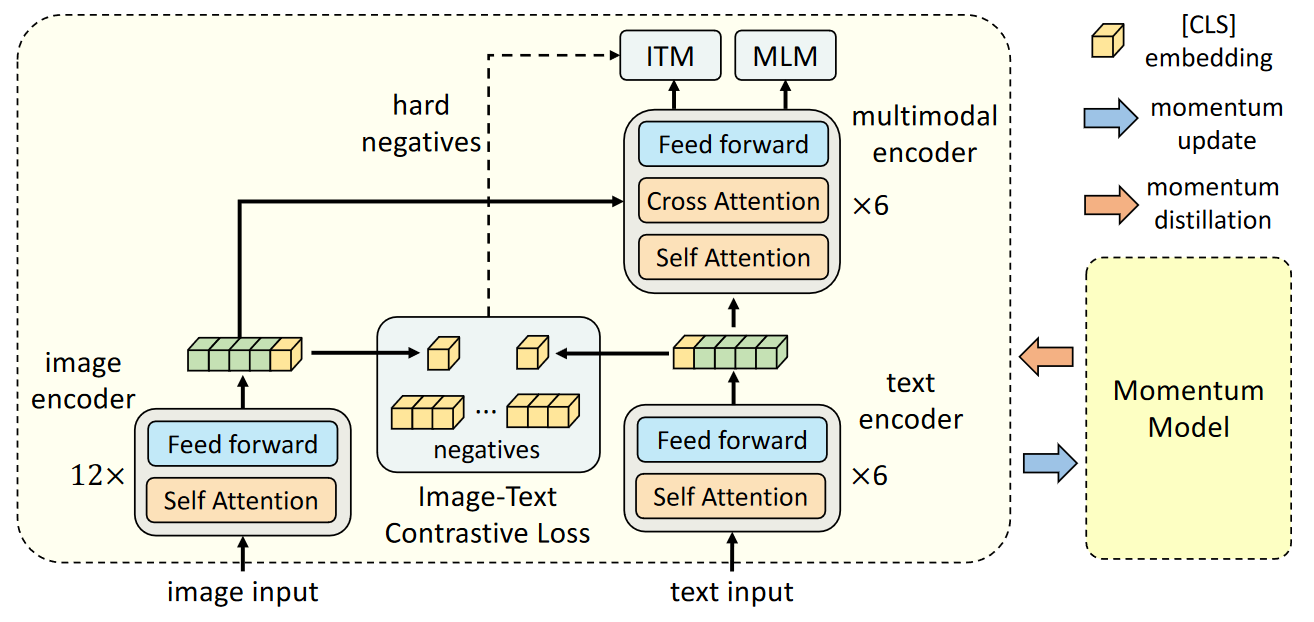
- 图像编码器使用的是12层visual transformer encoder ==ViT-B/16==, 并且用在ImageNet-1k预训练好的权重用于初始化。
- 图像编码器部分使用6层transformer encoder,使用==BERTbase==模型的前六层用于初始化。
- 模态融合层也使用6层transformer encoder,使用==BERTbase==模型的后六层进行初始化。
输入
- 图像 I 被图像编码器转换为一串嵌入序列: {==vcls==, v1,…,vN }
- 输入文本 T 被文本编码器编码为一串嵌入序列:{==wcls==, w1,…,wN }
损失函数
- 在单模态编码器上进行图像-文本对比学习(ITC),
- 在多模态编码器上进行屏蔽语言建模(MLM)和图像-文本匹配(ITM)。==(hard negatives)==
- 由于ITM的特性,将前期ITC获得的对比结果的匹配度第二高的图像-文本对当成==不匹配==来强行训练ITM。
损失函数详解
1. ITC :
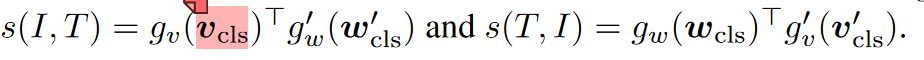
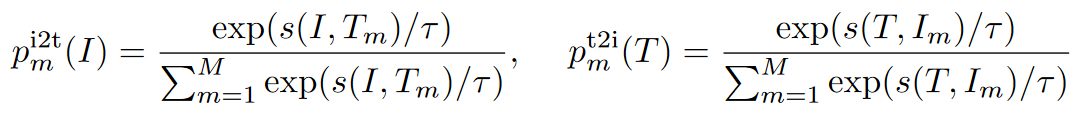
gv(vcls)^T^代表图像的特征gw(wcls)^T^代表文本的特征,g^/^v(v^/^cls)^T^则是来自动量模型的图像特征,g^/^w(w^/^cls)^T^是来自动量模型的文本特征。
gv和gw是将[CLS]嵌入映射到归化低维(256-d)表示的线性变换。
1 | p中的M代表动量模型中生成的最新M个图像文本表示。 |
2. MLM:
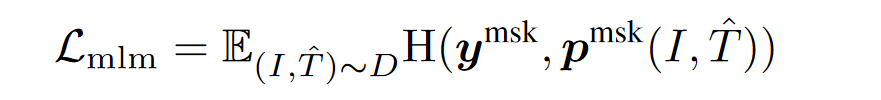
采用的依然是cross-entropy损失函数,T^^^代表被mask掉的文本,p^msk^代表预测的概率。(就是bert)
mask的概率是15%。
3. ITM:
图像-文本匹配预测的是—对图像和文本是积极的(匹配)还是消极的(不匹配)也就是==二分类==。我们使用多模态编码器对[CLS]标记的输出嵌入作为图像-文本对的联合表示,并附加一个全连接(FC)层,然后使用softmax预测两类概率p^itm^。ITM损失为:
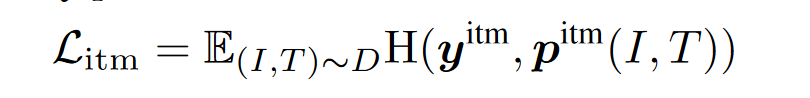
==这里的二分类就出现了使用ITC的第二匹配度的加强训练== ,因为正常的ITM只需要评价是否匹配上了但错误匹配太容易了,因此该函数会很快降下去。
4. 总损失函数
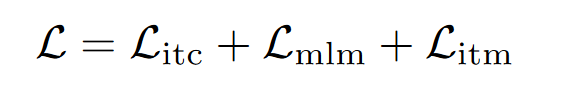
Momentum Distillation 动量蒸馏
用于预训练的图像-文本配对大多是从网络上收集的,它们往往是有噪声的。正文本对通常是弱相关的:文本可能包含与图像无关的词语,或者图像可能包含文本中没有描述的实体。==对于ITC学习来说,图像的负文本也可能与图像内容相匹配。对于MLM来说,可能存在与注释不同的基他词语,它们对图像的描述同样出色(或更好)。但是,ITC和MLM的单点标签会对所有负面预测进行惩罚,无论其正确与否==。
引入新loss
1.(Litc)^mod^
- 首先利用动量单模态编码器的特征计算图像-文本相似度,即
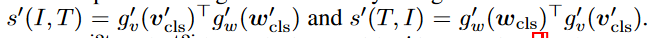
- 然后,我们用==s^/^代替softmax(就是上面ITC的p计算公式)中的s0,从而计算软伪目标q^i2t^和q^t2i^==。ITC
MoD损失定义为 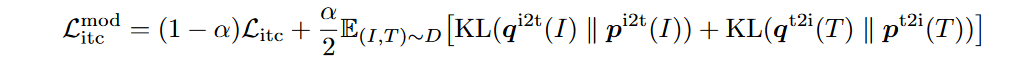
- 这里的q^i2t^和q^t2i^实际上就是==软化==的one-hot。以期在训练时遇到噪声标签时可以有一个调整。
2.(Lmlm)^mod
与上文类似替换。
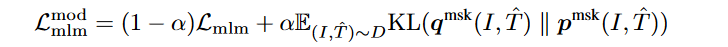
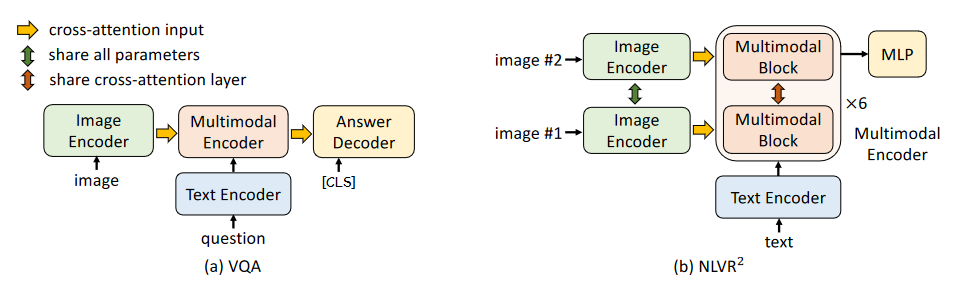
下游任务
可以把这个模型看成是一个提取特征的元器件,在不同的任务中只需要添加不同的输出头,或者把模块之间的组合稍加改变即可。